

PA3-穿越时空的旅程:批处理系统
最简单的操作系统
1. 批处理系统
- 批处理系统的思想:
- 事先准备好一组程序, 让计算机执行完一个程序之后, 就自动执行下一个程序
- 批处理系统的关键:
- 有一个后台程序, 当一个前台程序执行结束的时候, 后台程序就会自动加载一个新的前台程序来执行
- 这样的一个后台程序, 其实就是操作系统
- 操作系统具体又需要实现以下两点功能:
1
2- 用户程序执行结束之后, 可以跳转到操作系统的代码继续执行
- 操作系统可以加载一个新的用户程序来执行
1.1 来自操作系统的新需求
- 上述两点功能中其实蕴含着一个新的需求: 程序之间的执行流切换
- 能否也使用call/jal指令来实现程序之间的执行流切换呢?
- 如果操作系统崩溃了, 整个计算机系统都将无法工作. 所以希望能把操作系统保护起来。
- 所以这样太随意了
- 一种可以限制入口的执行流切换方式
- 显然, 这种方式是无法通过程序代码来实现的.
1.2 等级森严的制度
- eg:
RISC-V处理器存在M, S, U三个特权模式, 分别代表机器模式, 监管者模式和用户模式- M模式特权级最高, U模式特权级最低,
- 如何判断一个进程是否执行了无权限操作呢
- 在硬件上维护一个用于标识当前特权模式的寄存器(属于计算机状态的一部分), 然后在访问那些高特权级才能访问的资源时, 对当前特权模式进行检查.
- eg:
RISC-V中有一条特权指令sfence.vma, 手册要求只有当处理器当前的特权模式不低于S模式才能执行, 因此我们可以在硬件上添加一些简单的逻辑来实现特权模式的检查:is_sfence_vma_ok = (priv_mode == M_MODE) || (priv_mode == S_MODE);
- 如果检查不通过, 此次操作将会被判定为非法操作, CPU将会抛出异常信号, 并跳转到一个和操作系统约定好的内存位置, 交由操作系统进行后续处理.
- 通常来说, 操作系统运行在S模式, 因此有权限访问所有的代码和数据; 而一般的程序运行在U模式, 这就决定了它只能访问U模式的代码和数据. 这样, 只要操作系统将其私有代码和数据放S模式中, 恶意程序就永远没有办法访问到它们.
穿越时空的旅程
1. 穿越时空的旅程
- 自陷指令:硬件提供的一种可以限制入口的执行流切换方式
- 程序执行自陷指令之后, 就会陷入到操作系统预先设置好的跳转目标
- 异常入口地址:操作系统预先设置好的这个跳转目标
1.1 x86
- 提供
int指令作为自陷指令 - 异常入口地址是通过*门描述符(Gate Descriptor)*来指示
- 门描述符:一个8字节的结构体
- NEMU中简化了门描述符的结构, 只保留存在位P和偏移量OFFSET
- P位来用表示这一个门描述符是否有效
- OFFSET用来指示异常入口地址
- IDT(Interrupt Descriptor Table, 中断描述符表), 数组的一个元素就是一个门描述符
- 从数组中找到一个门描述符——索引
- 在内存中找到IDT——IDTR寄存器,存放IDT的首地址和长度
1.2 mips32
- 提供
syscall指令作为自陷指令 - 异常入口地址总是
0x80000180 - 0号协处理器(Co-Processor 0)
1.3 riscv32
- 提供
ecall指令作为自陷指令 mtvec寄存器来存放异常入口地址- 为了保存程序当前的状态, riscv32提供了一些特殊的系统寄存器, 叫控制状态寄存器(
CSR寄存器)- PA中, 我们只使用如下3个CSR寄存器:
- mepc寄存器 - 存放触发异常的PC
- mstatus寄存器 - 存放处理器的状态
- mcause寄存器 - 存放触发异常的原因
- riscv32触发异常后硬件的响应过程如下:
- 将当前PC值保存到mepc寄存器
- 在mcause寄存器中设置异常号
- 从mtvec寄存器中取出异常入口地址
- 跳转到异常入口地址
- riscv32通过
mret指令从异常处理过程中返回, 它将根据mepc寄存器恢复PC.
思考:特殊的原因? (建议二周目思考)
- 这些程序状态(x86的eflags, cs, eip; mips32的epc, status, cause; riscv32的mepc, mstatus, mcause)必须由硬件来保存吗? 能否通过软件来保存? 为什么?
- 理论上应该可以软件来保存,但是:
- 硬件保存这些状态寄存器比软件保存要快得多,因为硬件操作是直接的,而软件保存需要额外的指令和时间。
- 硬件保存状态寄存器在保存过程中不会被其他中断或异常打断。
- 软件保存状态需要额外的指令和代码,这会增加处理异常或中断的时间,降低系统性能,增加程序复杂性。
1.4 状态机视角下的异常响应机制
- 程序是个
S = <R, M>的状态机, 如果要给计算机添加异常响应机制, 我们又应该如何对这个状态机进行扩充呢?
- 首先,是对R的扩充
- 添加系统寄存器(System Register)
- 扩充之后的寄存器可以表示为
R = {GPR, PC, SR}
- 异常响应机制和内存无关, 无需对
M的含义进行修改 - 对状态转移的扩充
- 为了描述指令执行失败的行为, 我们可以假设CPU有一条虚构的指令
raise_intr,执行它的行为就是异常响应过程
1
2
3SR[mepc] <- PC
SR[mcause] <- 一个描述失败原因的号码
PC <- SR[mtvec]- 如果一条指令执行成功, 其行为和之前介绍的TRM与IOE相同; 如果一条指令执行失败, 其行为等价于执行了虚构的
raise_intr指令.
- 为了描述指令执行失败的行为, 我们可以假设CPU有一条虚构的指令
2. 将上下文管理抽象成CTE
- 操作系统的处理过程需要哪些信息
- 引发这次执行流切换的原因
- 程序的上下文
- 另外两个统一的API:
bool cte_init(Context* (*handler)(Event ev, Context *ctx))用于进行CTE相关的初始化操作. 其中它还接受一个来自操作系统的事件处理回调函数的指针, 当发生事件时, CTE将会把事件和相关的上下文作为参数, 来调用这个回调函数, 交由操作系统进行后续处理.void yield()用于进行自陷操作, 会触发一个编号为EVENT_YIELD事件. 不同的ISA会使用不同的自陷指令来触发自陷操作, 具体实现请RTFSC.
- 接下来, 我们尝试通过
am-tests中的yield test测试触发一次自陷操作, 来梳理过程中的细节
2.1 设置异常入口地址
- 当我们选择
yield test时,am-tests会通过cte_init()函数对CTE进行初始化, 其中包含一些简单的宏展开代码. 这最终会调用位于abstract-machine/am/src/$ISA/nemu/cte.c中的cte_init()函数.cte_init()函数会做两件事情, 第一件就是设置异常入口地址.- 对于riscv32来说, 直接将异常入口地址设置到mtvec寄存器中即可.
cte_init()函数做的第二件事是注册一个事件处理回调函数, 这个回调函数由yield test提供, 更多信息会在下文进行介绍.
2.2 触发自陷操作
- 从
cte_init()函数返回后,yield test将会调用测试主体函数hello_intr(), 首先输出一些信息, 然后通过io_read(AM_INPUT_CONFIG)启动输入设备(不过在NEMU中, 这一启动并无实质性操作). - 接下来
hello_intr()将通过iset(1)打开中断, 不过我们目前还没有实现中断相关的功能, 因此同样可以忽略这部分的代码. - 最后
hello_intr()将进入测试主循环: 代码将不断调用yield()进行自陷操作, 为了防止调用频率过高导致输出过快, 测试主循环中还添加了一个空循环用于空转.
- 为了支撑自陷操作, 同时测试异常入口地址是否已经设置正确, 你需要在NEMU中实现
isa_raise_intr()函数 (在nemu/src/isa/$ISA/system/intr.c中定义)来模拟上文提到的异常响应机制. - 需要注意的是:
- PA不涉及特权级的切换, RTFM的时候你不需要关心和特权级切换相关的内容.
- 你需要在自陷指令的实现中调用
isa_raise_intr(), 而不要把异常响应机制的代码放在自陷指令的helper函数中实现, 因为在后面我们会再次用到isa_raise_intr()函数.
必做:实现异常响应机制
- 你需要
- 实现上文提到的新指令,
- 实现
isa_raise_intr()函数 - 阅读
cte_init()的代码, 找出相应的异常入口地址.
- 如果你选择mips32和riscv32, 你会发现status/mstatus寄存器中有非常多状态位, 不过目前完全不实现这些状态位的功能也不影响程序的执行, 因此目前只需要将status/mstatus寄存器看成一个只用于存放32位数据的寄存器即可.
- 实现后, 重新运行
yield test, 如果你发现NEMU确实跳转到你找到的异常入口地址, 说明你的实现正确(NEMU也可能因为触发了未实现指令而终止运行).
- 实现新指令在
nemu/src/isa/riscv32/inst.c- 实现csr写指令
csrrw - 实现csr读指令
csrrs - 实现
ecall
- 实现csr写指令
1 | //csr相关宏定义 |
- 在
nemu/src/isa/riscv32/include/isa-def.h添加特殊寄存器
1 | typedef struct { |
- 在
nemu/src/isa/riscv32/system/intr.c中实现isa_raise_intr()函数:
1 | word_t isa_raise_intr(word_t NO, vaddr_t epc) { |
- 在
abstract-machine/am/src/riscv/nemu/cte.c中的cte_init()函数中找到异常入口地址。asm volatile("csrw mtvec, %0" : : "r"(__am_asm_trap));- 这行代码使用内联汇编指令
csrw mtvec, %0,将__am_asm_trap的地址写入 mtvec 寄存器。 - mtvec 寄存器用于存储异常入口地址,当发生异常时,程序会跳转到这个地址执行异常处理程序。
- 这行代码使用内联汇编指令
- 因此,异常入口地址是
__am_asm_trap的地址。
- 重新运行
yield tests:
- 在
am-kernels/tests/am-tests目录下make ARCH=riscv32-nemu run mainargs=i - NEMU确实跳转到你找到的异常入口地址, 说明你的实现正确(NEMU也可能因为触发了未实现指令而终止运行).
- 一直第一个指令就不行,很疑惑,改了好久实在是不知道哪里没好
- 结果发现是写指令的时候,把新写的csr相关指令不小心放到全“?”指令之后了,导致识别不到!
2.3 保存上下文
- 成功跳转到异常入口地址之后——开始真正的异常处理过程
- 上下文包括:
- 通用寄存器:
- riscv32通过sw指令将各个通用寄存器依次压栈.
- 触发异常时的PC和处理器状态:
- riscv32:
epc/mepc和status/mstatus寄存器, 异常响应机制把它们保存在相应的系统寄存器中, 我们还需要将它们从系统寄存器中读出, 然后保存在堆栈上.
- riscv32:
- 异常号:
- riscv32中, 异常号已经由硬件保存在
cause/mcause寄存器中, 我们还需要将其保存在堆栈上.
- riscv32中, 异常号已经由硬件保存在
- 地址空间:
- (这是为PA4准备的)riscv32是将地址空间信息与0号寄存器共用存储空间, 反正0号寄存器的值总是0, 也不需要保存和恢复. 不过目前我们暂时不使用地址空间信息, 你目前可以忽略它们的含义.
- 通用寄存器:
思考:异常号的保存
- x86通过软件来保存异常号, 没有类似cause的寄存器. mips32和riscv32也可以这样吗? 为什么?
- 对于 mips32 和 riscv32 架构,它们都有专门的寄存器(如 cause 寄存器)来保存异常号。这些寄存器的存在有以下几个原因:
- 性能:硬件寄存器保存异常号比通过软件保存要快得多,减少了异常处理的开销。
- 简化设计:硬件寄存器使得异常处理更加简单和直接,减少了软件处理的复杂性。
- 一致性:硬件寄存器可以确保在异常发生时立即保存异常号,避免了在软件保存过程中可能出现的竞态条件。
- 虽然 mips32 和 riscv32 理论上可以通过软件来保存异常号,但这样做会带来性能下降和设计复杂性增加的问题。因此,使用硬件寄存器来保存异常号是更为合理和高效的选择。
思考:对比异常处理与函数调用
- 我们知道进行函数调用的时候也需要保存调用者的状态: 返回地址, 以及calling convention中需要调用者保存的寄存器. 而
CTE在保存上下文的时候却要保存更多的信息. 尝试对比它们, 并思考两者保存信息不同是什么原因造成的.
- 函数调用时的状态保存
- 以便在函数执行完毕后能够正确返回并继续执行。保存的状态包括:
- 返回地址:函数执行完毕后需要返回的地址。
- 调用者保存的寄存器:根据调用约定(calling convention),需要调用者保存的寄存器(如 x86 中的 ebx, esi, edi 等)。
- 异常处理(
CTE)时的状态保存- 保存更多的信息,以便在处理完异常后能够正确恢复并继续执行。保存的状态包括:
- 程序计数器(PC):发生异常时的指令地址。
- 状态寄存器:处理器的状态(如 x86 中的 eflags,mips32 中的 status,riscv32 中的 mstatus)。
- 异常号:表示发生了哪种异常(如 mips32 中的 cause,riscv32 中的 mcause)。
- 其他上下文信息:可能包括更多的寄存器和处理器状态,以确保异常处理程序能够正确执行。
- 保存信息不同的原因
- 复杂性:异常处理比函数调用更复杂,因为异常可能发生在任何时候,处理器需要保存更多的状态信息以确保能够正确恢复执行。
- 原子性:异常处理需要确保状态保存和恢复的原子性,以避免在处理中断或异常时出现竞态条件。
- 硬件支持:异常处理通常由硬件直接支持,硬件可以快速保存和恢复状态,而函数调用主要由软件管理,保存的状态较少。
- 恢复执行:函数调用的返回地址和调用者保存的寄存器足以恢复执行,而异常处理需要保存更多的状态信息,以确保在处理完异常后能够正确恢复到异常发生前的状态。
- 接下来代码会调用C函数
__am_irq_handle()(在abstract-machine/am/src/$ISA/nemu/cte.c中定义), 来进行异常的处理.
必做:重新组织Context结构体
- 你的任务如下:
- 实现这一过程中的新指令, 详情请RTFM.
- 理解上下文形成的过程并RTFSC, 然后重新组织
abstract-machine/am/include/arch/$ISA-nemu.h(如果你选择RISC-V, 则文件名为riscv.h) 中定义的Context结构体的成员, 使得这些成员的定义顺序和abstract-machine/am/src/$ISA/nemu/trap.S中构造的上下文保持一致.
- 需要注意的是, 虽然我们目前暂时不使用上文提到的地址空间信息, 但你在重新组织Context结构体时仍然需要正确地处理地址空间信息的位置, 否则你可能会在PA4中遇到难以理解的错误.
- 实现之后, 你可以在
__am_irq_handle()中通过printf输出上下文c的内容, 然后通过简易调试器观察触发自陷时的寄存器状态, 从而检查你的Context实现是否正确.
- 实现新指令:
INSTPAT("0011000 00010 00000 000 00000 11100 11", mret , N, s->dnpc = CSR(0x341));
- 在````abstract-machine/am/include/arch/riscv.h
中,通过trap.S``重排Context:
- 分析:在
trap.S中:- #define CONTEXT_SIZE ((NR_REGS + 3) * XLEN)
- NR_REGS:表示通用寄存器的数量——通用寄存器
- #define OFFSET_SP ( 2 * XLEN)
- OFFSET_SP:表示堆栈指针(SP)在上下文中的偏移量——*pdir
- #define OFFSET_CAUSE ((NR_REGS + 0) * XLEN)
- mcause
- #define OFFSET_STATUS ((NR_REGS + 1) * XLEN)
- mstatus
- #define OFFSET_EPC ((NR_REGS + 2) * XLEN)
- mepc
- #define CONTEXT_SIZE ((NR_REGS + 3) * XLEN)
1 | struct Context { |
- 在
abstract-machine/am/src/riscv/nemu/cte.c的__am_irq_handle()函数中,通过printf输出上下文c的内容:
1 | Context* __am_irq_handle(Context *c) {//异常处理函数 |
必做:必答题(需要在实验报告中回答) - 理解上下文结构体的前世今生
- 你会在__am_irq_handle()中看到有一个上下文结构指针c, c指向的上下文结构究竟在哪里? 这个上下文结构又是怎么来的? 具体地, 这个上下文结构有很多成员, 每一个成员究竟在哪里赋值的? $ISA-nemu.h, trap.S, 上述讲义文字, 以及你刚刚在NEMU中实现的新指令, 这四部分内容又有什么联系?
- 如果你不是脑袋足够灵光, 还是不要眼睁睁地盯着代码看了, 理解程序的细节行为还是要从状态机视角入手.
- c指向的上下文结构的来源:
- 上下文结构体
Context是在异常处理过程中创建的。它包含了处理器的寄存器状态,包括通用寄存器、异常号、处理器状态和异常 PC 等。
- 上下文结构体
- 上下文结构体的创建过程
- 异常触发:当发生异常时,处理器会自动跳转到异常处理入口地址,该地址存储在
mtvec寄存器中。ps:这个地址是__am_asm_trap。 - 保存上下文:在
__am_asm_trap中,使用汇编代码保存当前的处理器状态到栈中。具体来说,将所有通用寄存器、mcause、mstatus 和 mepc 寄存器的值保存到栈中。 - 调用异常处理函数:保存完上下文后,我们将栈指针传递给
__am_irq_handle函数,并调用它进行异常处理。
- 异常触发:当发生异常时,处理器会自动跳转到异常处理入口地址,该地址存储在
- 上下文结构体的成员赋值:
- 在
trap.S中被赋值
- 保存通用寄存器:
MAP(REGS, PUSH)- 使用宏
PUSH将所有通用寄存器的值保存到栈中。
- 使用宏
- 保存mcause、mstatus和mepc寄存器:
1
2
3
4
5
6
7csrr t0, mcause
csrr t1, mstatus
csrr t2, mepc
STORE t0, OFFSET_CAUSE(sp)
STORE t1, OFFSET_STATUS(sp)
STORE t2, OFFSET_EPC(sp)- 使用
csrr指令将mcause、mstatus 和 mepc寄存器的值读取到临时寄存器t0、t1 和 t2,然后使用STORE宏将它们保存到栈中。
- 使用
- 在
- 各部分内容的联系
riscv.h:定义了上下文结构体 Context,包括通用寄存器、mcause、mstatus 和 mepc 等成员。trap.S:在异常发生时,保存处理器的状态到栈中,并调用 __am_irq_handle 进行异常处理。cte.c:实现了异常处理函数 __am_irq_handle,通过指针 c 访问上下文结构体,并输出其成员的值。- 新指令的实现:在 inst.c 中实现了
csrr和csrw指令,用于读取和写入 CSR 寄存器的值。这些指令在 trap.S 中被使用,用于保存和恢复 mcause、mstatus 和 mepc 寄存器的值。
2.4 事件分发
__am_irq_handle()的代码会把执行流切换的原因打包成事件, 然后调用在cte_init()中注册的事件处理回调函数, 将事件交给yield test来处理.- 在
yield test中, 这一回调函数是am-kernels/tests/am-tests/src/tests/intr.c中的simple_trap()函数.simple_trap()函数会根据事件类型再次进行分发. 不过我们在这里会触发一个未处理的事件:AM Panic: Unhandled event @ am-kernels/tests/am-tests/src/tests/intr.c:12
- 因为CTE的
__am_irq_handle()函数并未正确识别出自陷事件. 根据yield()的定义,__am_irq_handle()函数需要将自陷事件打包成编号为EVENT_YIELD的事件.
必做:识别自陷事件
- 你需要在
__am_irq_handle()中通过异常号识别出自陷异常, 并打包成编号为EVENT_YIELD的自陷事件. 重新运行yield test, 如果你的实现正确, 你会看到识别到自陷事件之后输出一个字符y.
- 在
__am_irq_handle()中:
1 | switch (c->mcause) { |
- 运行yield test效果:(有输出y,但很快很多,接着往下看吧!)
1 | Hello, AM World @ riscv32 |
2.5 恢复上下文
- 代码将会一路返回到
trap.S的__am_asm_trap()中, 接下来的事情就是恢复程序的上下文. - 之前自陷指令保存的PC,对于riscv32的ecall, 保存的是自陷指令的PC
- 因此软件需要在适当的地方对保存的PC加上4, 使得将来返回到自陷指令的下一条指令.
- 代码最后会返回到
yield test触发自陷的代码位置, 然后继续执行
思考:从加4操作看CISC和RISC
- 事实上, 自陷只是其中一种异常类型. 有一种故障类异常, 它们返回的PC和触发异常的PC是同一个, 例如缺页异常, 在系统将故障排除后, 将会重新执行相同的指令进行重试, 因此异常返回的PC无需加4. 所以根据异常类型的不同, 有时候需要加4, 有时候则不需要加.
- 这时候, 我们就可以考虑这样的一个问题了: 决定要不要加4的, 是硬件还是软件呢? CISC和RISC的做法正好相反, CISC都交给硬件来做, 而RISC则交给软件来做. 思考一下, 这两种方案各有什么取舍? 你认为哪种更合理呢? 为什么?
- 硬件 vs 软件决定加4
- CISC(复杂指令集计算机):通常由硬件决定是否加4。硬件会根据异常类型自动调整PC。
- RISC(精简指令集计算机):通常由软件决定是否加4。软件在异常处理程序中根据异常类型调整PC。
- 取舍分析
- 硬件决定(CISC):
- 优点:
- 简化软件设计:软件不需要关心异常类型和PC的调整,减少了异常处理程序的复杂性。
- 快速响应:硬件直接处理,速度更快。
- 缺点:
- 硬件复杂度增加:硬件需要识别各种异常类型并做出相应处理,增加了硬件设计的复杂性。
- 灵活性较低:硬件实现的处理方式固定,软件无法灵活调整。
- 优点:
- 软件决定(RISC):
- 优点:
- 硬件简单:硬件只需触发异常,不需要处理PC的调整,简化了硬件设计。
- 灵活性高:软件可以根据具体需求灵活调整PC,适应不同的异常处理需求。
- 缺点:
- 增加软件复杂性:异常处理程序需要识别异常类型并调整PC,增加了软件设计的复杂性。
- 响应速度较慢:软件处理需要额外的指令,可能导致响应速度较慢。
- 优点:
- 硬件决定(CISC):
- 我认为合理性取决于设计目标,
- 如果系统设计目标是简化软件开发,提高响应速度,CISC的硬件决定方式可能更合理。
- 如果系统设计目标是简化硬件设计,提高灵活性,RISC的软件决定方式可能更合理。
必做:恢复上下文
- 你需要实现这一过程中的新指令. 重新运行
yield test. 如果你的实现正确,yield test将不断输出y.
- 在
mret指令处进行“+4”:INSTPAT("0011000 00010 00000 000 00000 11100 11", mret , N, s->dnpc = CSR(0x341)+4);
- 实现后效果:不断输出y(有节奏地输出y,没有疯狂输出了,而是遇到再输出)
1 | Hello, AM World @ riscv32 |
必答题(需要在实验报告中回答) - 理解穿越时空的旅程
- 从
yield test调用yield()开始, 到从yield()返回的期间, 这一趟旅程具体经历了什么? 软(AM,yield test)硬(NEMU)件是如何相互协助来完成这趟旅程的? 你需要解释这一过程中的每一处细节, 包括涉及的每一行汇编代码/C代码的行为, 尤其是一些比较关键的指令/变量. 事实上, 上文的必答题”理解上下文结构体的前世今生”已经涵盖了这趟旅程中的一部分, 你可以把它的回答包含进来. - 别被”每一行代码”吓到了, 这个过程也就大约50行代码, 要完全理解透彻并不是不可能的. 我们之所以设置这道必答题, 是为了强迫你理解清楚这个过程中的每一处细节. 这一理解是如此重要, 以至于如果你缺少它, 接下来你面对bug几乎是束手无策.
yield()函数调用- 在
yield test中,调用yield()函数:
1
2
3
4
5
6
7void yield() {
asm volatile("li a5, -1; ecall");
asm volatile("li a7, -1; ecall");
}- 这段代码使用内联汇编触发一个环境调用(ECALL)
li a7, -1:将立即数 -1 加载到寄存器 a7 中ecall:触发一个环境调用异常。
- 在
- 触发异常
ecall指令触发一个环境调用异常,处理器进入异常处理模式,并跳转到由mtvec寄存器指定的异常处理程序地址。
- 异常处理程序(在
trap.S文件中定义):addi sp, sp, -CONTEXT_SIZE: 为保存上下文分配空间。MAP(REGS, PUSH): 保存所有通用寄存器的值。csrr t0, mcause: 读取 mcause 寄存器的值到 t0。csrr t1, mstatus: 读取 mstatus 寄存器的值到 t1。csrr t2, mepc: 读取 mepc 寄存器的值到 t2。STORE t0, OFFSET_CAUSE(sp): 将 mcause 的值保存到栈中。STORE t1, OFFSET_STATUS(sp): 将 mstatus 的值保存到栈中。STORE t2, OFFSET_EPC(sp): 将 mepc 的值保存到栈中。li a0, (1 << 17): 将立即数 1 << 17 加载到 a0 中。or t1, t1, a0: 将 t1 和 a0 进行或运算,结果存入 t1。csrw mstatus, t1: 将 t1 的值写入 mstatus 寄存器。mv a0, sp: 将栈指针的值移动到 a0。call __am_irq_handle: 调用 __am_irq_handle 函数。
__am_irq_handle函数(在cte.c文件中定义):switch (c->mcause):根据 mcause 的值判断异常类型。case 0: ev.event = EVENT_YIELD; break;:如果 mcause 为 0,表示自陷异常,将事件类型设置为 EVENT_YIELD。c = user_handler(ev, c);:调用用户注册的事件处理程序 user_handler,并传递事件和上下文。
- 用户事件处理程序(在
intr.c文件中定义):case EVENT_YIELD: putch('y'); break;:如果事件类型为 EVENT_YIELD,输出字符 y。
- 恢复上下文并返回
- 回到异常处理程序:
LOAD t1, OFFSET_STATUS(sp):从栈中恢复 mstatus 的值到 t1。LOAD t2, OFFSET_EPC(sp):从栈中恢复 mepc 的值到 t2。csrw mstatus, t1:将 t1 的值写入 mstatus 寄存器。csrw mepc, t2:将 t2 的值写入 mepc 寄存器。MAP(REGS, POP):恢复所有通用寄存器的值。addi sp, sp, CONTEXT_SIZE:释放为保存上下文分配的空间。mret:从异常处理程序返回,恢复程序的正常执行。
2.6 异常处理的踪迹-etrace
必做:实现etrace
- 在
isa_raise_intr中添加:
1 | //etrace |
- 效果(运行yield test):
1 | Hello, AM World @ riscv32 |
PA 3.1到此结束
用户程序和系统调用
1. 最简单的操作系统
- 在PA中使用的操作系统叫
Nanos-lite, 它是南京大学操作系统Nanos的裁剪版 - Nanos-lite的框架代码, 通过执行以下命令获取:
1 | cd ics2024 |
- 会通过
nanos-lite/include/common.h中一些与实验进度相关的宏来控制Nanos-lite的功能 - 由于Nanos-lite本质上也是一个AM程序, 我们可以采用相同的方式来编译/运行Nanos-lite. 在nanos-lite/目录下执行
make ARCH=$ISA-nemu run即可 - 需要在
nanos-lite/include/common.h中定义宏HAS_CTE, 这样以后, Nanos-lite会多进行以下操作:- 初始化时调用init_irq()函数, 它将通过cte_init()函数初始化CTE
- 在panic()前调用yield()来触发自陷操作
必做:为Nanos-lite实现正确的事件分发
Nanos-lite的事件处理回调函数默认不处理所有事件, 你需要在其中识别出自陷事件EVENT_YIELD, 然后输出一句话即可, 目前无需进行其它操作.- 重新运行Nanos-lite, 如果你的实现正确, 你会看到识别到自陷事件之后输出的信息, 并且最后仍然触发了main()函数末尾设置的panic().
- 在
nanos-lite/include/common.h中定义宏HAS_CTE
1 |
ics2024/nanos-lite/src/irq.c:(中断异常处理)
1 | static Context* do_event(Event e, Context* c) { |
- 现在运行
make ARCH=riscv32-nemu run,得到有识别到自陷事件之后输出的信息, 也有触发main()函数末尾设置的panic():
1 | mcause = -1 |
2. 加载第一个用户程序
- 在操作系统中, 加载用户程序是由loader(加载器)模块负责的
- 加载的过程就是把可执行文件中的代码和数据放置在正确的内存位置, 然后跳转到程序入口, 程序就开始执行了
- 为了实现loader()函数, 我们需要解决以下问题:
- 可执行文件在哪里?
- 代码和数据在可执行文件的哪个位置?
- 代码和数据有多少?
- “正确的内存位置”在哪里?
- 用户程序是从哪里来的
- 准备了一个新的子项目Navy-apps, 专门用于编译出操作系统的用户程序
1 | cd ics2024 |
- 用户程序的入口位于
navy-apps/libs/libos/src/crt0/start.S中的_start()函数- 这里的crt是C RunTime的缩写, 0的含义表示最开始.
_start()函数会- 调用
navy-apps/libs/libos/src/crt0/crt0.c中的call_main()函数 - 然后调用用户程序的main()函数
- 从main()函数返回后会调用exit()结束运行.
- 调用
- C库的代码”总是”对的
- 要在Nanos-lite上运行的第一个用户程序是
navy-apps/tests/dummy/dummy.c- 为了编译dummy, 在
navy-apps/tests/dummy/目录下执行make ISA=$ISA - 一直编译不了,终端执行了
export NAVY_HOME=/home/xiaoyao/ics2024/navy-apps之后可以了 - 编译成功后把
navy-apps/tests/dummy/build/dummy-$ISA手动复制并重命名为nanos-lite/build/ramdisk.img, 然后在nanos-lite/目录下执行make ARCH=$ISA-nemu会生成Nanos-lite的可执行文件,
- 为了编译dummy, 在
思考:堆和栈在哪里?
- 我们提到了代码和数据都在可执行文件里面, 但却没有提到堆(heap)和栈(stack). 为什么堆和栈的内容没有放入可执行文件里面? 那程序运行时刻用到的堆和栈又是怎么来的? AM的代码是否能给你带来一些启发?
- 堆和栈的内容没有放入可执行文件里面的原因如下:
- 堆和栈的动态性:
- 栈:栈用于存储函数调用的局部变量、函数参数和返回地址等。栈的大小和内容在程序运行时是动态变化的,随着函数的调用和返回,栈上的数据不断变化。
- 堆:堆用于动态分配内存,程序在运行时可以根据需要分配和释放内存。堆的大小和内容也是动态变化的,取决于程序的运行情况。
- 可执行文件的静态性:
- 可执行文件在编译时生成,包含了程序的代码段和数据段。这些内容在程序运行时是相对固定的,不会像堆和栈那样动态变化。
- 堆和栈的初始化:
- 栈:栈在程序启动时由操作系统或运行时环境初始化。通常,栈的起始地址和大小在程序加载时由操作系统分配。
- 堆:堆在程序运行时由操作系统或运行时环境管理。程序通过动态内存分配函数(如 malloc、free 等)来请求和释放堆内存。
- 堆和栈的动态性:
- AM代码的启发:
- AM 的代码中有初始化堆和栈的部分。例如,在操作系统启动时,会设置栈指针(SP)和堆指针(HP),并为它们分配初始内存区域。
思考:如何识别不同格式的可执行文件?
- 从如果你在GNU/Linux下执行一个从Windows拷过来的可执行文件, 将会报告”格式错误”. 思考一下, GNU/Linux是如何知道”格式错误”的?
- 在 GNU/Linux 下,操作系统通过检查可执行文件的文件头(header)来识别不同格式的可执行文件。每种可执行文件格式都有其特定的文件头结构和魔数(magic number),操作系统可以通过这些信息来判断文件的格式是否正确。
- 以下是一些常见的可执行文件格式及其魔数:
- ELF(Executable and Linkable Format):
- ELF 是 GNU/Linux 系统中常见的可执行文件格式。
- ELF 文件的魔数是 0x7F ‘E’ ‘L’ ‘F’,即文件的前四个字节是 0x7F 45 4C 46。
- PE(Portable Executable):
- PE 是 Windows 系统中常见的可执行文件格式。
- PE 文件的魔数是 0x4D 5A,即文件的前两个字节是 MZ(DOS MZ 可执行文件标记)。
- Mach-O:
- Mach-O 是 macOS 系统中常见的可执行文件格式。
- Mach-O 文件的魔数是 0xFEEDFACE 或 0xCAFEBABE,具体取决于文件的字节序。
- ELF(Executable and Linkable Format):
- 当你在 GNU/Linux 下执行一个从 Windows 拷贝过来的可执行文件时,操作系统会检查文件头的魔数。如果魔数不匹配,操作系统会报告“格式错误”。
思考: 冗余的属性?
- 使用readelf查看一个ELF文件的信息, 你会看到一个segment包含两个大小的属性, 分别是FileSiz和MemSiz, 这是为什么? 再仔细观察一下, 你会发现FileSiz通常不会大于相应的MemSiz, 这又是为什么?
- FileSiz 和 MemSiz 的含义:
- FileSiz:表示段在文件中的大小。即该段在磁盘上的实际存储大小。
- MemSiz:表示段在内存中的大小。即该段在程序加载到内存后占用的大小。
- 为什么需要两个属性:
- 某些段在加载到内存后需要额外的空间来存储运行时数据。例如,BSS 段(未初始化数据段)在文件中可能只占用很小的空间(甚至为零),但在内存中需要分配实际的大小来存储未初始化的全局变量。
- 通过区分 FileSiz 和 MemSiz,操作系统可以正确地分配内存并初始化段的内容。例如,对于 BSS 段,操作系统会根据 MemSiz 分配内存,并将其内容初始化为零。
- 为什么 FileSiz 通常不会大于 MemSiz:
- 通常情况下,段在文件中的大小不会超过其在内存中的大小,因为文件中的内容是段的实际数据,而内存中的内容可能包含额外的运行时数据。
- 例如,代码段(text segment)和已初始化数据段(data segment)的 FileSiz 和 MemSiz 通常是相等的,因为它们在文件中和内存中的大小是一致的。
- 对于 BSS 段,FileSiz 通常为零,而 MemSiz 则表示需要分配的内存大小。
思考:为什么要清零?
- 为什么需要将
[VirtAddr + FileSiz, VirtAddr + MemSiz)对应的物理区间清零? - 原因:
- 未初始化数据段(BSS 段):
- 在 ELF 文件中,BSS 段(未初始化数据段)通常在文件中不占用空间(FileSiz 为 0),但在内存中需要分配实际的大小(MemSiz)。
- BSS 段用于存储未初始化的全局变量和静态变量,这些变量在程序启动时默认初始化为零。
- 因此,需要将 BSS 段对应的内存区域清零,以确保这些变量在程序运行时被正确初始化为零。
- 安全性和一致性:
- 清零内存区域可以防止程序访问未初始化的内存,从而避免潜在的安全漏洞和未定义行为。
- 确保内存区域的一致性,使得程序在不同环境下运行时具有相同的初始状态。
- 内存分配的规范:
- 根据内存分配的规范,未初始化的数据段在加载到内存时应该被清零。这是操作系统和运行时环境的一部分职责。
必做:实现loader
- 你需要在
Nanos-lite中实现loader的功能, 来把用户程序加载到正确的内存位置, 然后执行用户程序.- loader()函数在
nanos-lite/src/loader.c中定义, 其中的pcb参数目前暂不使用, 可以忽略, 而因为ramdisk中目前只有一个文件, filename参数也可以忽略. 在下一个阶段实现文件系统之后, filename就派上用场了.
- loader()函数在
- 实现后, 在
init_proc()中调用naive_uload(NULL, NULL), 它会调用你实现的loader来加载第一个用户程序, 然后跳转到用户程序中执行.- 如果你的实现正确, 你会看到执行dummy程序时在Nanos-lite中触发了一个未处理的4号事件. 这说明loader已经成功加载dummy, 并且成功地跳转到dummy中执行了. 关于未处理的事件, 我们会在下文进行说明.
- 在
loader.c中:
1 |
|
- 新建loader.h
1 | void naive_uload(PCB *pcb, const char *filename); |
- 新建ramdisk.h
1 |
|
- 在proc.c中:
1 |
|
- 运行效果:
- 出现了system panic: Unhandled event ID = 4,与文档所说相符合
1 | [/home/xiaoyao/ics2024/nanos-lite/src/irq.c,8,do_event] system panic: Unhandled event ID = 4 |
选做:检查ELF文件的魔数
- 我们知道ELF文件的开头都有一个特殊的魔数, 为了防止loader加载了一个非ELF格式的文件, 我们可以在loader中对魔数进行检查:
1 | assert(*(uint32_t *)elf->e_ident == 0xBadC0de); |
- 你需要把上述的0xBadC0de换成正确的魔数.
- 别小看这个表面上很蠢的assert(), 当你哪天手抖不知道做了什么而又被它抓到的时候, 你就知道谢天谢地了.
- 在loader.c中:
1 | static uintptr_t loader(PCB *pcb, const char *filename) { |
3. 操作系统的运行时环境
思考:系统调用的必要性
- 对于批处理系统来说, 系统调用是必须的吗? 如果直接把AM的API暴露给批处理系统中的程序, 会不会有问题呢?
- 对于批处理系统来说,系统调用是必须的。以下是原因和直接暴露 AM(Abstract Machine)API 给批处理系统中的程序可能带来的问题:
- 资源管理和保护:
- 系统调用:系统调用提供了一种受控的方式来访问系统资源。操作系统可以通过系统调用来管理和保护资源,确保资源的合理分配和使用,防止程序之间的相互干扰。
- 直接暴露 AM API:如果直接暴露 AM 的 API 给程序,程序可以直接访问硬件资源。这会导致资源管理混乱,程序之间可能会相互干扰,覆盖彼此的内存空间或屏幕内容,导致系统不稳定。
- 安全性:
- 系统调用:系统调用通过特权级别的转换来保护系统资源。用户程序在请求系统资源时,需要通过系统调用进入内核态,由操作系统进行权限检查和资源分配。
- 直接暴露 AM API:直接暴露 AM API 给程序,程序可以绕过操作系统直接访问硬件资源,可能会导致安全漏洞,恶意程序可以利用这些漏洞破坏系统或窃取敏感信息。
- 抽象和简化:
- 系统调用:系统调用提供了一种抽象的接口,隐藏了底层硬件的复杂性,使得程序员可以更方便地编写应用程序,而不需要关心底层硬件的细节。
- 直接暴露 AM API:直接暴露 AM API 给程序,程序员需要了解底层硬件的细节,增加了编程的复杂性和出错的可能性。
- 可移植性:
- 系统调用:系统调用提供了一种标准化的接口,使得应用程序可以在不同的硬件平台上运行,只需要操作系统提供相应的系统调用实现。
- 直接暴露 AM API:直接暴露 AM API 给程序,程序与特定硬件平台紧密耦合,降低了程序的可移植性。
- 资源管理和保护:
4. 系统调用
- 触发一个系统调用的具体过程是怎么样的呢?
- 在
GNU/Linux中, 用户程序通过自陷指令来触发系统调用,Nanos-lite也沿用这个约定 - CTE中的
yield()也是通过自陷指令来实现 - 那么对用户程序来说, 用来向操作系统描述需求的最方便手段就是使用通用寄存器
- 执行自陷指令之后, 执行流就会马上切换到事先设置好的入口, 通用寄存器也会作为上下文的一部分被保存起来
- 系统调用处理函数只需要从上下文中获取必要的信息, 就能知道用户程序发出的服务请求是什么了.
- Navy已经为用户程序准备好了系统调用的接口了.
navy-apps/libs/libos/src/syscall.c中定义的_syscall_()函数已经蕴含着上述过程:- 先把系统调用的参数依次放入寄存器中, 然后执行自陷指令.
- 由于寄存器和自陷指令都是ISA相关的, 因此这里根据不同的ISA定义了不同的宏, 来对它们进行抽象.
- CTE会将这个自陷操作打包成一个系统调用事件EVENT_SYSCALL, 并交由Nanos-lite继续处理.
1 | intptr_t _syscall_(intptr_t type, intptr_t a0, intptr_t a1, intptr_t a2) { |
必做:识别系统调用
- 目前
dummy已经通过_syscall_()直接触发系统调用, 你需要让Nanos-lite识别出系统调用事件EVENT_SYSCALL. - 处理器通常只会提供一条自陷指令, 这时EVENT_SYSCALL和EVENT_YIELD 都通过相同的自陷指令来实现, 因此CTE需要额外的方式区分它们. 如果自陷指令本身可以携带参数, 就可以用不同的参数指示不同的事件, 例如x86和mips32都可以采用这种方式; 如果自陷指令本身不能携带参数, 那就需要通过其他状态来区分, 一种方式是通过某个寄存器的值来区分, riscv32采用这种方式.
- 你可能需要对多处代码进行修改, 当你为代码无法实现正确而感到疑惑时, 请检查这个过程中的每一个细节. 我们已经强调了很多次, 理解细节是很重要的.
1 | Context* __am_irq_handle(Context *c) { |
必做:实现SYS_yield系统调用
- 你需要:
- 在
abstract-machine/am/include/arch/目录下的相应头文件中实现正确的GPR?宏, 让它们从上下文c中获得正确的系统调用参数寄存器. - 添加
SYS_yield系统调用. - 设置系统调用的返回值.
- 在
- 重新运行dummy程序, 如果你的实现正确, 你会看到dummy程序又触发了一个号码为0的系统调用. 查看
nanos-lite/src/syscall.h, 你会发现它是一个SYS_exit系统调用. 这说明之前的SYS_yield已经成功返回, 触发SYS_exit是因为dummy已经执行完毕, 准备退出了.
- 在
abstract-machine/am/include/arch/目录下的相应头文件就是riscv.h
1 |
- 先补充完整syscall.h,再在irq.c中:
1 |
|
- 在syscall.c中,do_syscall:
1 | void do_syscall(Context *c) { |
- 成功,dummy程序又触发了一个号码为0的系统调用
1 | [/home/xiaoyao/ics2024/nanos-lite/src/syscall.c,12,do_syscall] system panic: Unhandled syscall ID = 0 |
- 查看nanos-lite/src/syscall.h, 你会发现它是一个SYS_exit系统调用
必做:实现SYS_exit系统调用
- 你需要实现
SYS_exit系统调用, 它会接收一个退出状态的参数. 为了方便测试, 我们目前先直接使用这个参数调用halt(). 实现成功后, 再次运行dummy程序, 你会看到HIT GOOD TRAP的信息.
1 | case 0: |
- 成功!
[src/cpu/cpu-exec.c:196 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x800004e4
5. 系统调用的踪迹:
必做:实现strace
6. 操作系统之上的TRM
标准输出
- 根据write的函数声明(参考man 2 write), 你需要在do_syscall()中识别出系统调用号是SYS_write之后, 检查fd的值, 如果fd是1或2(分别代表stdout和stderr), 则将buf为首地址的len字节输出到串口(使用putch()即可). 最后还要设置正确的返回值, 否则系统调用的调用者会认为write没有成功执行, 从而进行重试. 至于write系统调用的返回值是什么, 请查阅man 2 write. 另外不要忘记在navy-apps/libs/libos/src/syscall.c的_write()中调用系统调用接口函数.
必做:在Nanos-lite上运行Hello world
- Navy中提供了一个
hello测试程序(navy-apps/tests/hello), 它首先通过write()来输出一句话, 然后通过printf()来不断输出. - 你需要实现
write()系统调用, 然后把Nanos-lite上运行的用户程序切换成hello程序来运行.
- 在do_syscall中补充+完成FSwrite
1 | void do_syscall(Context *c) { |
- 切换成hallo程序
- 运行,
HIT GOOD TRAP at pc = 0x80000560但是没有正确输出! - 没找出问题,先往后看
- (实现堆区管理后成功了)
堆区管理
- 调整堆区大小是通过sbrk()库函数来实现的, 它的原型是
1 | void* sbrk(intptr_t increment); |
必做:实现堆区管理
- 根据上述内容在Nanos-lite中实现
SYS_brk系统调用, 然后在用户层实现_sbrk(). 你可以通过man 2 sbrk来查阅libc中brk()和sbrk()的行为, 另外通过man 3 end来查阅如何使用_end符号. - 需要注意的是, 调试的时候不要在
_sbrk()中通过printf()进行输出, 这是因为printf()还是会尝试通过malloc()来申请缓冲区, 最终会再次调用_sbrk(), 造成死递归. 你可以通过sprintf()先把调试信息输出到一个字符串缓冲区中, 然后通过_write()进行输出. - 如果你的实现正确, 你可以借助
strace看到printf()不再是逐个字符地通过write()进行输出, 而是将格式化完毕的字符串通过一次性进行输出.
- 在do_syscall中补充
1 | case 9:// brk |
- 在
/navy-apps/libs/libos/src/syscall.c中:
1 | extern char _end; |
- 成功!
1 | Hello World! |
必答题:hello程序是什么, 它从而何来, 要到哪里去
(见文档最后)
PA3.2结束
文件系统
1. 简易文件系统
必做:让loader使用文件+实现完整的文件系统
- 我们之前是让loader来直接调用
ramdisk_read()来加载用户程序. ramdisk中的文件数量增加之后, 这种方式就不合适了, 我们首先需要让loader享受到文件系统的便利. - 你需要先实现
fs_open(),fs_read()和fs_close(), 这样就可以在loader中使用文件名来指定加载的程序了, 例如”/bin/hello”. - 实现之后, 以后更换用户程序只需要修改传入
naive_uload()函数的文件名即可. - 实现
fs_write()和fs_lseek(), 然后运行测试程序navy-apps/tests/file-test. 为了编译它, 你需要把它加到navy-apps/Makefile的TESTS变量中, 这样它最终就会被包含在ramdisk镜像中. 这个测试程序用于进行一些简单的文件读写和定位操作. 如果你的实现正确, 你将会看到程序输出**PASS!!!**的信息.
- 补充do_syscall()
1 | case SYS_open://open |
- libos:
1 | int _open(const char *path, int flags, mode_t mode) { |
- fs.c
1 | typedef struct { |
- loader.c更改:
- ramdisk改成fs
- proc.c更改程序
1 | naive_uload(NULL, "/bin/file-test"); |
- makefile添加file-test到TEST
- 记得update再run——更新应用程序列表
- 成功
1 | PASS!!! |
支持sfs的strace
- 由于sfs的特性, 打开同一个文件总是会返回相同的文件描述符. 这意味着, 我们可以把strace中的文件描述符直接翻译成文件名, 得到可读性更好的trace信息. 尝试实现这一功能, 它可以为你将来使用strace提供一些便利.
2. 一切皆文件
- 文件就是字节序列
- 为不同的事物提供了统一的接口: 我们可以使用文件的接口来操作计算机上的一切, 而不必对它们进行详细的区分
虚拟文件系统 VFS
- VFS其实是对不同种类的真实文件系统的抽象, 它用一组API来描述了这些真实文件系统的抽象行为, 屏蔽了真实文件系统之间的差异, 上层模块(比如系统调用处理函数)不必关心当前操作的文件具体是什么类型, 只要调用这一组API即可完成相应的文件操作.
- 有了VFS的概念, 要添加一个真实文件系统就非常容易了: 只要把真实文件系统的访问方式包装成VFS的API, 上层模块无需修改任何代码, 就能支持一个新的真实文件系统了.
- 在Nanos-lite中, 实现VFS的关键就是Finfo结构体中的两个读写函数指针:
1 | typedef struct { |
- 其中ReadFn和WriteFn分别是两种函数指针, 它们用于指向真正进行读写的函数, 并返回成功读写的字节数. 有了这两个函数指针, 我们只需要在文件记录表中对不同的文件设置不同的读写函数, 就可以通过
f->read()和f->write()的方式来调用具体的读写函数了. - 约定, 当上述的函数指针为NULL时, 表示相应文件是一个普通文件, 通过ramdisk的API来进行文件的读写,
操作系统之上的IOE
- 在Nanos-lite中, stdout和stderr都会输出到串口. 之前你可能会通过判断fd是否为1或2, 来决定
sys_write()是否写入到串口 - 有了VFS, 只需要在
nanos-lite/src/device.c中实现serial_write(), 然后在文件记录表中设置相应的写函数, 就可以实现上述功能 - 由于串口是一个字符设备, 对应的字节序列没有”位置”的概念, 因此
serial_write()中的offset参数可以忽略. - 另外Nanos-lite也不打算支持stdin的读入, 因此在文件记录表中设置相应的报错函数即可.
必做:把串口抽象成文件
- 根据上述内容, 让VFS支持串口的写入.
- 在
nanos-lite/src/device.c中实现serial_write(),并在common.h里补充函数原型
1 | size_t serial_write(const void *buf, size_t offset, size_t len) { |
- 在文件记录表中设置相应的写函数:在
nanos-lite/src/fs.c中,将stdout和stderr的写函数设置为serial_write()
1 | static Finfo file_table[] __attribute__((used)) = { |
- 修改
fs_read()和fs_write():
1 | //read添加 |
- 运行helo来检验:成功!
必做:实现gettimeofday
- 实现gettimeofday系统调用, 这一系统调用的参数含义请RTFM. 实现后, 在navy-apps/tests/中新增一个timer-test测试, 在测试中通过gettimeofday()获取当前时间, 并每过0.5秒输出一句话.
- 实现
SYS_gettimeofday系统调用,syscall.c中:
1 | void do_syscall(Context *c) { |
- libos
1 | int _gettimeofday(struct timeval *tv, struct timezone *tz) { |
- 新增
timer-test测试程序
1 | //timer-test.c |
1 | NAME = timer-test |
- 在
navy-apps/Makefile中将timer-test添加到TESTS变量中 - 测试,成功!
必做:实现NDL的时钟
- 你需要用
gettimeofday()实现NDL_GetTicks(), 然后修改timer-test测试, 让它通过调用NDL_GetTicks()来获取当前时间. 你可以根据需要在NDL_Init()和NDL_Quit()中添加初始化代码和结束代码, 我们约定程序在使用NDL库的功能之前必须先调用NDL_Init(). 如果你认为无需添加初始化代码, 则无需改动它们.
- NDL.c:
1 |
|
- 修改测试
1 |
|
- timer-test的makefile里添加
1 | LIBS = libndl |
- 运行检验,成功!
必做:把按键输入抽象成文件
- 你需要:
- 实现
events_read()(在nanos-lite/src/device.c中定义), 把事件写入到buf中, 最长写入len字节, 然后返回写入的实际长度. 其中按键名已经在字符串数组names中定义好了, 你需要借助IOE的API来获得设备的输入. 另外, 若当前没有有效按键, 则返回0即可. - 在VFS中添加对
/dev/events的支持. - 在NDL中实现
NDL_PollEvent(), 从/dev/events中读出事件并写入到buf中.
- 实现
- 我们可以假设一次最多只会读出一个事件, 这样可以简化你的实现. 实现后, 让Nanos-lite运行
navy-apps/tests/event-test, 如果实现正确, 敲击按键时程序会输出按键事件的信息.
- 实现 events_read() 函数,将事件写入到 buf 中。
1 | size_t events_read(void *buf, size_t offset, size_t len) { |
- 在 VFS 中添加对 /dev/events 的支持。
1 | //fs.c |
- 在 NDL 中实现 NDL_PollEvent(),从 /dev/events 中读出事件并写入到 buf 中。
1 |
|
- 改一下,运行event-test
- 成功!
1 | receive event: keydown W |
必做:在NDL中获取屏幕大小
- 实现
dispinfo_read()(在nanos-lite/src/device.c中定义), 按照约定将文件的len字节写到buf中(我们认为这个文件不支持lseek, 可忽略offset). - 在NDL中读出这个文件的内容, 从中解析出屏幕大小, 然后实现
NDL_OpenCanvas()的功能. 目前NDL_OpenCanvas()只需要记录画布的大小就可以了, 当然我们要求画布大小不能超过屏幕大小. - 让Nanos-lite运行
navy-apps/tests/bmp-test, 由于目前还没有实现绘图功能, 因此无法输出图像内容, 但你可以先通过printf()输出解析出的屏幕大小.
- 实现
dispinfo_read()函数,按照约定将文件的内容写到 buf 中。
1 | size_t dispinfo_read(void *buf, size_t offset, size_t len) { |
- fs.c
1 | [FD_DISP] = {"/proc/dispinfo", 0, 0, dispinfo_read, invalid_write}, |
- 在 NDL 中读出
/proc/dispinfo文件的内容,从中解析出屏幕大小。
1 | int NDL_Init(uint32_t flags) { |
- 实现
NDL_OpenCanvas()的功能,记录画布的大小
1 | void NDL_OpenCanvas(int *w, int *h) { |
- 实现
NDL_DrawRect()的功能,向画布 (x, y) 坐标处绘制 w*h 的矩形图像
1 | void NDL_DrawRect(uint32_t *pixels, int x, int y, int w, int h) { |
必做:把VGA显存抽象成文件
- 在
init_fs()(在nanos-lite/src/fs.c中定义)中对文件记录表中/dev/fb的大小进行初始化. - 实现
fb_write()(在nanos-lite/src/device.c中定义), 用于把buf中的len字节写到屏幕上offset处. 你需要先从offset计算出屏幕上的坐标, 然后调用IOE来进行绘图. 另外我们约定每次绘图后总是马上将frame buffer中的内容同步到屏幕上. - 在NDL中实现
NDL_DrawRect(), 通过往/dev/fb中的正确位置写入像素信息来绘制图像. 你需要梳理清楚系统屏幕(即frame buffer),NDL_OpenCanvas()打开的画布, 以及NDL_DrawRect()指示的绘制区域之间的位置关系. - 让Nanos-lite运行
navy-apps/tests/bmp-test, 如果实现正确, 你将会看到屏幕上显示Project-N的logo.
nanos-lite/src/fs.c中的init_fs()函数中对/dev/fb的大小进行初始化:
1 | void init_fs() { |
- 在
nanos-lite/src/device.c中实现fb_write()函数:
1 | size_t fb_write(const void *buf, size_t offset, size_t len) { |
- 在
navy-apps/libs/libndl/NDL.c中实现NDL_DrawRect()函数:
1 | void NDL_DrawRect(uint32_t *pixels, int x, int y, int w, int h) { |
- 成功!
精彩纷呈的应用程序
1. 更丰富的运行时环境
多媒体库
- miniSDL的代码位于
navy-apps/libs/libminiSDL/目录下, 它由6个模块组成:- timer.c: 时钟管理
- event.c: 事件处理
- video.c: 绘图接口
- file.c: 文件抽象
- audio.c: 音频播放
- general.c: 常规功能, 包括初始化, 错误管理等
定点算术
- 定点数也可以实现实数!,而且定点数的运算可以通过整数运算来实现, 意味着我们可以通过整数运算指令来实现实数的逻辑, 而无需在硬件上引入FPU来运行这些程序. 这样的一个算术体系称为定点算术.
- Navy中提供了一个fixedptc的库, 专门用于进行定点算术. fixedptc库默认采用32位整数来表示实数, 其具体格式为”24.8” (见
navy-apps/libs/libfixedptc/include/fixedptc.h), 表示整数部分占24位, 小数部分占8位, 也可以认为实数的小数点总是固定位于第8位二进制数的左边. - fixedpt类型的常见运算
- 加法可以直接用整数加法来进行
- 减法可以用整数减法来进行
- 乘法,相乘后将结果除以2^8
- 除法,结果再乘以2^8
- 关系运算,都可以用整数的关系运算来进行
必做:实现更多的fixedptc API
- 为了让大家更好地理解定点数的表示, 我们在
fixedptc.h中去掉了一些API的实现, 你需要实现它们. - 关于
fixedpt_floor()和fixedpt_ceil(), 你需要严格按照man中floor()和ceil()的语义来实现它们, 否则在程序中用fixedpt_floor()代替floor()之后行为会产生差异, 在类似仙剑奇侠传这种规模较大的程序中, 这种差异导致的现象是非常难以理解的. 因此你也最好自己编写一些测试用例来测试你的实现.
- 补充
1 | /* Multiplies a fixedpt number with an integer, returns the result. */ |
- 编写测试用例
1 |
|
- 测试结果,正确
1 | fixedpt_floor(1.2) = 1 |
Navy作为基础设施
- 你可以在bmp-test所在的目录下运行
make ISA=native run, 来把bmp-test编译到Navy native上并直接运行, 还可以通过make ISA=native gdb对它进行调试. 这样你就可以在Linux native的环境下单独测试Navy中除了libos和Newlib之外的所有代码了(例如NDL和miniSDL). 一个例外是Navy中的dummy, 由于它通过_syscall_()直接触发系统调用, 这样的代码并不能直接在Linux native上直接运行, 因为Linux不存在这个系统调用(或者编号不同).
2. Navy中的应用程序
NSlider (NJU Slider)
- 一个支持翻页的幻灯片播放器
- 需要实现以下两个与Surface相关的API:
SDL_BlitSurface(): 将一张画布中的指定矩形区域复制到另一张画布的指定位置SDL_UpdateRect(): 将画布中的指定矩形区域同步到屏幕上
必做:运行NSlider
- 我们提供了一个脚本来把PDF版本的, 比例为4:3的幻灯片转换成BMP图像, 并拷贝到
navy-apps/fsimg/中. 你需要提供一个满足条件的PDF文件, 然后参考相应的README文件进行操作. 但你可能会在转换时遇到一些问题, 具体请自行解决. - 然后在miniSDL中实现
SDL_BlitSurface()和SDL_UpdateRect(). 如果你的实现正确, 运行NSlider时将会显示第一张幻灯片. 你很可能是第一次接触SDL的API, 为此你还需要RTFM, 并通过RTFSC来理解已有代码的行为.
SDL_BlitSurface()用于将一张画布中的指定矩形区域复制到另一张画布的指定位置。我们需要确保源画布和目标画布的像素格式相同。
1 | void SDL_BlitSurface(SDL_Surface *src, SDL_Rect *srcrect, SDL_Surface *dst, SDL_Rect *dstrect) { |
SDL_UpdateRect()用于将画布中的指定矩形区域同步到屏幕上。我们需要调用NDL_DrawRect()来实现这一功能。
1 | void SDL_UpdateRect(SDL_Surface *s, int x, int y, int w, int h) { |
- 查看nslider的readme
- 将 slides.pdf 复制到
slides/目录 - 运行
convert.sh - 修改
src/main.cpp中的变量N为幻灯片的总数
- 将 slides.pdf 复制到
- 记得app:nslider
必做:运行NSlider(2)
- 在miniSDL中实现
SDL_WaitEvent(), 它用于等待一个事件. 你需要将NDL中提供的事件封装成SDL事件返回给应用程序, 具体可以通过阅读NSlider的代码来理解SDL事件的格式. 实现正确后, 你就可以在NSlider中进行翻页了, 翻页的操作方式请RTFSC.
- debug好久才发现是最后的\n没去掉!!!
1 | //event.c |
- 成功

MENU (开机菜单)
- 开机菜单是另一个行为比较简单的程序, 它会展示一个菜单, 用户可以选择运行哪一个程序. 为了运行它, 你还需要在miniSDL中实现
SDL_FillRect(), 它用于往画布的指定矩形区域中填充指定的颜色. - 开机菜单还会显示一些英文字体, 这些字体的信息以BDF格式存储, Navy中提供了一个libbdf库来解析BDF格式, 生成相应字符的像素信息, 并封装成SDL的Surface. 有了
SDL_BlitSurface()之后, 我们就可以很方便地在屏幕上输出字符串的像素信息了.
必做:运行开机菜单
- 正确实现上述API后, 你将会看到一个可以翻页的开机菜单. 但你尝试选择菜单项的时候将会出现错误, 这是因为开机菜单的运行还需要一些系统调用的支持. 我们会在下文进行介绍, 目前通过开机菜单来测试miniSDL即可.
- SDL_FillRect
1 | void SDL_FillRect(SDL_Surface *dst, SDL_Rect *dstrect, uint32_t color) { |
- debug非常痛苦最后发现是
NDL_OpenCanvas,
1 | if (*w == 0 && *h == 0) { |
- 应该放在循环外
- 终于成功TAT
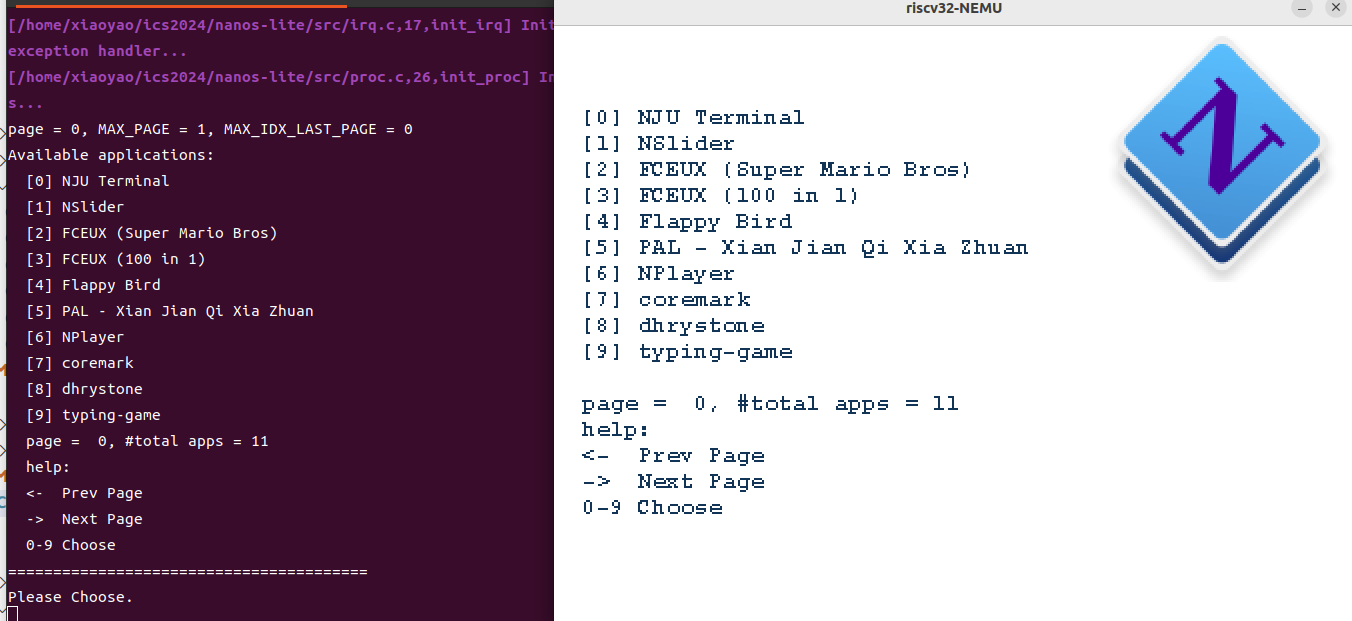
NTerm (NJU Terminal)
- NTerm是一个模拟终端, 它实现了终端的基本功能, 包括字符的键入和回退, 以及命令的获取等. 终端一般会和Shell配合使用, 从终端获取到的命令将会传递给Shell进行处理, Shell又会把信息输出到终端. NTerm自带一个非常简单的內建Shell(见
builtin-sh.cpp), 它默认忽略所有的命令. NTerm也可以和外部程序进行通信, 但这超出了ICS的范围, 我们在PA中不会使用这个功能. - 为了运行NTerm, 你还需要实现miniSDL的两个API:
SDL_GetTicks(): 它和NDL_GetTicks()的功能类似, 但有一个额外的小要求, 具体请RTFMSDL_PollEvent(): 它和SDL_WaitEvent()不同的是, 如果当前没有任何事件, 就会立即返回
必做:运行NTerm
- 正确实现上述API后, 你会看到NTerm的光标以每秒一次的频率闪烁, 并且可以键入字符. 为了让NTerm可以启动其它程序, 你还需要实现一些系统调用, 我们会在下文进行介绍.
1 | static uint32_t start_ticks = 0; |
1 | int SDL_PollEvent(SDL_Event *event) { |
- 成功!
Flappy Bird
- 在
navy-apps/apps/bird/目录下运行make init, 将会从github上克隆移植后的项目 - 为了在Navy中运行
Flappy Bird, 你还需要实现另一个库SDL_image中的一个API:IMG_Load()
必做:运行Flappy Bird
- 实现
IMG_Load(), 在Navy中运行Flappy Bird. 这本质上是一个文件操作的练习. 另外, Flappy Bird默认使用400像素的屏幕高度, 但NEMU的屏幕高度默认为300像素, 为了在NEMU运行Flappy Bird, 你需要将navy-apps/apps/bird/repo/include/Video.h中的 SCREEN_HEIGHT修改为300. - Flappy Bird默认还会尝试打开声卡播放音效, miniSDL默认会让音频相关的API返回0或NULL, 程序会认为相应操作失败, 但仍然可以在无音效的情况下运行.
- 在对应目录下克隆
PAL(仙剑奇侠传)
- 在
navy-apps/apps/pal/目录下运行make init, 将会从github上克隆移植后的项目.
必做:运行仙剑奇侠传
- 为miniSDL中的绘图API添加8位像素格式的支持. 实现正确之后, 你就可以看到游戏画面了. 为了操作, 你还需要实现其它的API, 具体要实现哪些API, 就交给你来寻找吧. 实现正确后, 你就可以在自己实现的NEMU中运行仙剑奇侠传了!
- 你可以在游戏中进行各种操作来对你的实现进行测试, 我们提供的数据文件中包含一些游戏存档, 5个存档中的场景分别如下, 可用于进行不同的测试:
- 无敌人的机关迷宫
- 无动画的剧情
- 有动画的剧情
- 已进入敌人视野的迷宫
- 未进入敌人视野的迷宫
- 为miniSDL中的*绘图API添加8位像素格式的支持
1 | //以及SDL_BlitSurface |
- 补充完善按键
1 | uint8_t* SDL_GetKeyState(int *numkeys) { |
- 成功!!
- 画面是偏移的,修改一下
1 | //NDL.h |
- 画面成功到最中间啦!!
- 测试一下
- 无敌人的机关迷宫
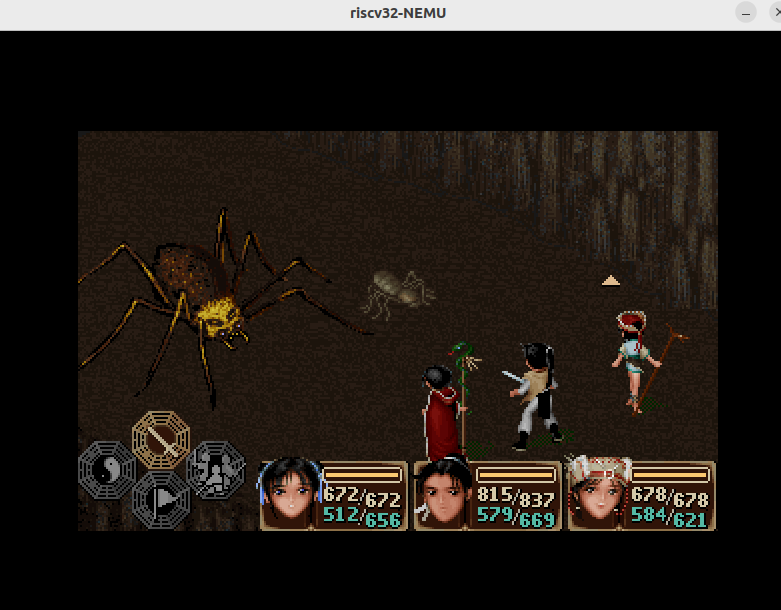
- 无动画的剧情
- 有动画的剧情
- 已进入敌人视野的迷宫
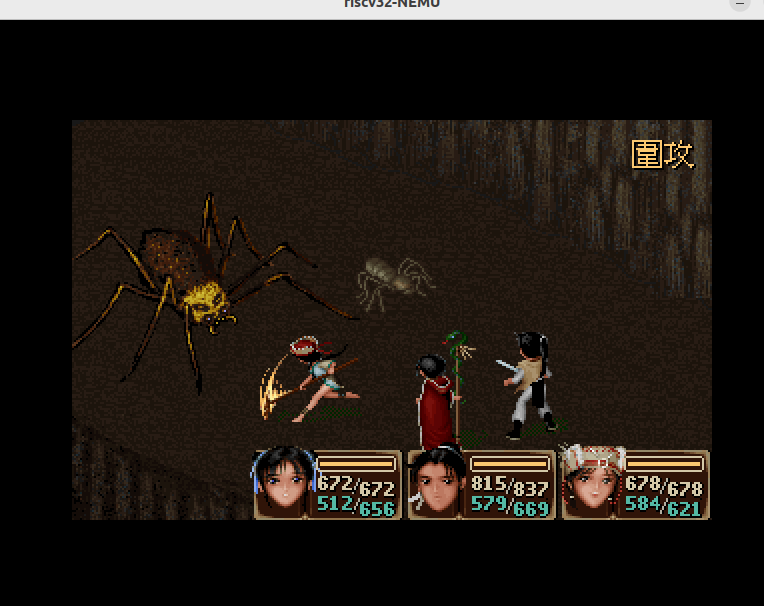
- 未进入敌人视野的迷宫
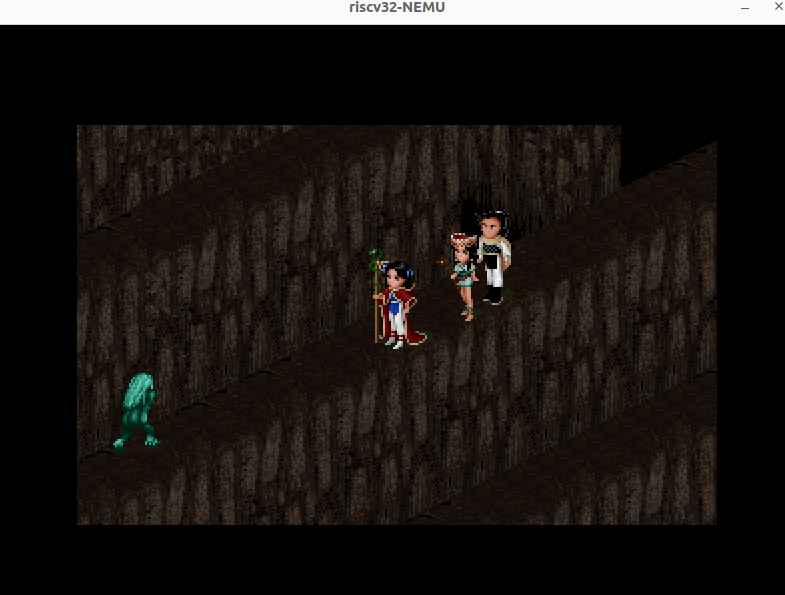
3. 展示你的批处理系统
- “执行其它程序”需要一个新的系统调用来支持, 这个系统调用就是
SYS_execve- 它的作用是结束当前程序的运行, 并启动一个指定的程序
- 为了实现这个系统调用, 你只需要在相应的系统调用处理函数中调用
naive_uload()就可以了. 目前我们只需要关心filename即可,argv和envp这两个参数可以暂时忽略.
必做:可以运行其它程序的开机菜单
- 你需要实现
SYS_execve系统调用, 然后通过开机菜单来运行其它程序. 你已经实现过很多系统调用了, 需要注意哪些细节, 这里就不啰嗦了.
1 | //do_syscall() |
- 成功
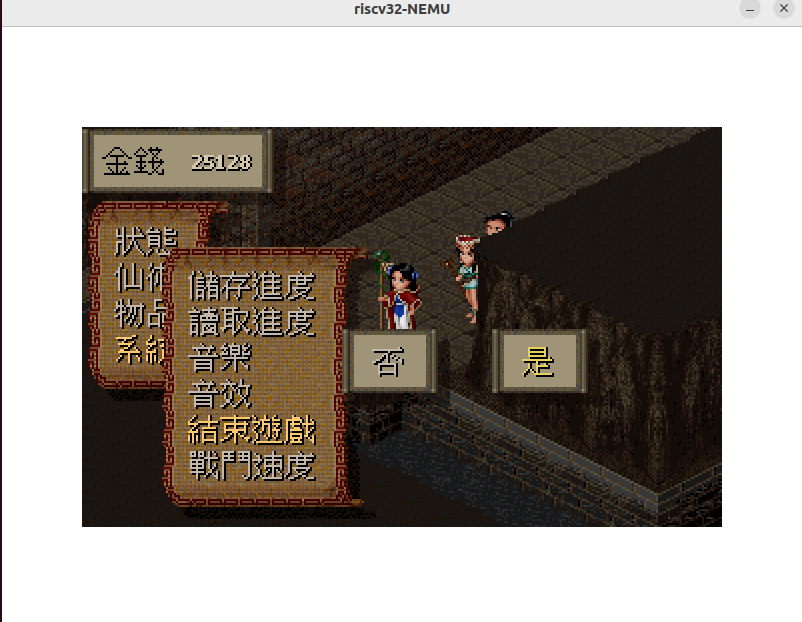
必做:展示你的批处理系统
- 有了开机菜单程序之后, 就可以很容易地实现一个有点样子的批处理系统了. 你只需要修改
SYS_exit的实现, 让它调用SYS_execve来再次运行/bin/menu, 而不是直接调用halt()来结束整个系统的运行. 这样以后, 在一个用户程序结束的时候, 操作系统就会自动再次运行开机菜单程序, 让用户选择一个新的程序来运行.
1 | //do_syscall |
- 成功
必做:展示你的批处理系统(2)
- 在NTerm的內建Shell中实现命令解析, 把键入的命令作为参数调用
execve(). 然后把NTerm作为Nanos-lite第一个启动的程序, 并修改SYS_exit的实现, 让它再次运行/bin/nterm. 目前我们暂不支持参数的传递, 你可以先忽略命令的参数.
1 | //builtin-sh.cpp |
- 成功!
必做:为NTerm中的內建Shell添加环境变量的支持
- 这是一个非常简单的任务, 你只需要RTFM了解
setenv()和execvp()的行为, 并对內建Shell的代码进行少量修改, 就可以得到一个和你平时的使用体验非常相似的Shell了.
1 | static void sh_handle_cmd(const char *cmd) { |
- 成功!

必答题:理解计算机系统
- 理解上下文结构体的前世今生 (见PA3.1阶段)
- 理解穿越时空的旅程 (见PA3.1阶段)
- hello程序是什么, 它从而何来, 要到哪里去 (见PA3.2阶段)
- 仙剑奇侠传究竟如何运行 运行仙剑奇侠传时会播放启动动画, 动画里仙鹤在群山中飞过. 这一动画是通过navy-apps/apps/pal/repo/src/main.c中的PAL_SplashScreen()函数播放的. 阅读这一函数, 可以得知仙鹤的像素信息存放在数据文件mgo.mkf中. 请回答以下问题: 库函数, libos, Nanos-lite, AM, NEMU是如何相互协助, 来帮助仙剑奇侠传的代码从mgo.mkf文件中读出仙鹤的像素信息, 并且更新到屏幕上? 换一种PA的经典问法: 这个过程究竟经历了些什么? (Hint: 合理使用各种trace工具, 可以帮助你更容易地理解仙剑奇侠传的行为)
理解上下文结构体的前世今生
- 你会在__am_irq_handle()中看到有一个上下文结构指针c, c指向的上下文结构究竟在哪里? 这个上下文结构又是怎么来的? 具体地, 这个上下文结构有很多成员, 每一个成员究竟在哪里赋值的? $ISA-nemu.h, trap.S, 上述讲义文字, 以及你刚刚在NEMU中实现的新指令, 这四部分内容又有什么联系?
- 如果你不是脑袋足够灵光, 还是不要眼睁睁地盯着代码看了, 理解程序的细节行为还是要从状态机视角入手.
- c指向的上下文结构的来源:
- 上下文结构体
Context是在异常处理过程中创建的。它包含了处理器的寄存器状态,包括通用寄存器、异常号、处理器状态和异常 PC 等。
- 上下文结构体
- 上下文结构体的创建过程
- 异常触发:当发生异常时,处理器会自动跳转到异常处理入口地址,该地址存储在
mtvec寄存器中。ps:这个地址是__am_asm_trap。 - 保存上下文:在
__am_asm_trap中,使用汇编代码保存当前的处理器状态到栈中。具体来说,将所有通用寄存器、mcause、mstatus 和 mepc 寄存器的值保存到栈中。 - 调用异常处理函数:保存完上下文后,我们将栈指针传递给
__am_irq_handle函数,并调用它进行异常处理。
- 异常触发:当发生异常时,处理器会自动跳转到异常处理入口地址,该地址存储在
- 上下文结构体的成员赋值:
- 在
trap.S中被赋值
- 保存通用寄存器:
MAP(REGS, PUSH)- 使用宏
PUSH将所有通用寄存器的值保存到栈中。
- 使用宏
- 保存mcause、mstatus和mepc寄存器:
1
2
3
4
5
6
7csrr t0, mcause
csrr t1, mstatus
csrr t2, mepc
STORE t0, OFFSET_CAUSE(sp)
STORE t1, OFFSET_STATUS(sp)
STORE t2, OFFSET_EPC(sp)- 使用
csrr指令将mcause、mstatus 和 mepc寄存器的值读取到临时寄存器t0、t1 和 t2,然后使用STORE宏将它们保存到栈中。
- 使用
- 在
- 各部分内容的联系
riscv.h:定义了上下文结构体 Context,包括通用寄存器、mcause、mstatus 和 mepc 等成员。trap.S:在异常发生时,保存处理器的状态到栈中,并调用 __am_irq_handle 进行异常处理。cte.c:实现了异常处理函数 __am_irq_handle,通过指针 c 访问上下文结构体,并输出其成员的值。- 新指令的实现:在 inst.c 中实现了
csrr和csrw指令,用于读取和写入 CSR 寄存器的值。这些指令在 trap.S 中被使用,用于保存和恢复 mcause、mstatus 和 mepc 寄存器的值。
理解穿越时空的旅程
- 从
yield test调用yield()开始, 到从yield()返回的期间, 这一趟旅程具体经历了什么? 软(AM,yield test)硬(NEMU)件是如何相互协助来完成这趟旅程的? 你需要解释这一过程中的每一处细节, 包括涉及的每一行汇编代码/C代码的行为, 尤其是一些比较关键的指令/变量. 事实上, 上文的必答题”理解上下文结构体的前世今生”已经涵盖了这趟旅程中的一部分, 你可以把它的回答包含进来. - 别被”每一行代码”吓到了, 这个过程也就大约50行代码, 要完全理解透彻并不是不可能的. 我们之所以设置这道必答题, 是为了强迫你理解清楚这个过程中的每一处细节. 这一理解是如此重要, 以至于如果你缺少它, 接下来你面对bug几乎是束手无策.
yield()函数调用- 在
yield test中,调用yield()函数:
1
2
3
4
5
6
7void yield() {
asm volatile("li a5, -1; ecall");
asm volatile("li a7, -1; ecall");
}- 这段代码使用内联汇编触发一个环境调用(ECALL)
li a7, -1:将立即数 -1 加载到寄存器 a7 中ecall:触发一个环境调用异常。
- 在
- 触发异常
ecall指令触发一个环境调用异常,处理器进入异常处理模式,并跳转到由mtvec寄存器指定的异常处理程序地址。
- 异常处理程序(在
trap.S文件中定义):addi sp, sp, -CONTEXT_SIZE: 为保存上下文分配空间。MAP(REGS, PUSH): 保存所有通用寄存器的值。csrr t0, mcause: 读取 mcause 寄存器的值到 t0。csrr t1, mstatus: 读取 mstatus 寄存器的值到 t1。csrr t2, mepc: 读取 mepc 寄存器的值到 t2。STORE t0, OFFSET_CAUSE(sp): 将 mcause 的值保存到栈中。STORE t1, OFFSET_STATUS(sp): 将 mstatus 的值保存到栈中。STORE t2, OFFSET_EPC(sp): 将 mepc 的值保存到栈中。li a0, (1 << 17): 将立即数 1 << 17 加载到 a0 中。or t1, t1, a0: 将 t1 和 a0 进行或运算,结果存入 t1。csrw mstatus, t1: 将 t1 的值写入 mstatus 寄存器。mv a0, sp: 将栈指针的值移动到 a0。call __am_irq_handle: 调用 __am_irq_handle 函数。
__am_irq_handle函数(在cte.c文件中定义):switch (c->mcause):根据 mcause 的值判断异常类型。case 0: ev.event = EVENT_YIELD; break;:如果 mcause 为 0,表示自陷异常,将事件类型设置为 EVENT_YIELD。c = user_handler(ev, c);:调用用户注册的事件处理程序 user_handler,并传递事件和上下文。
- 用户事件处理程序(在
intr.c文件中定义):case EVENT_YIELD: putch('y'); break;:如果事件类型为 EVENT_YIELD,输出字符 y。
- 恢复上下文并返回
- 回到异常处理程序:
LOAD t1, OFFSET_STATUS(sp):从栈中恢复 mstatus 的值到 t1。LOAD t2, OFFSET_EPC(sp):从栈中恢复 mepc 的值到 t2。csrw mstatus, t1:将 t1 的值写入 mstatus 寄存器。csrw mepc, t2:将 t2 的值写入 mepc 寄存器。MAP(REGS, POP):恢复所有通用寄存器的值。addi sp, sp, CONTEXT_SIZE:释放为保存上下文分配的空间。mret:从异常处理程序返回,恢复程序的正常执行。
hello程序是什么, 它从而何来, 要到哪里去
- hello程序从C源文件到在终端上打印字符串,经历了编译、链接、加载、执行等多个步骤:
- hello程序一开始在哪里?
- 一开始在源文件
navy-apps/tests/hello/hello.c。这个源文件通过编译器(如GCC)编译成目标文件,然后通过链接器链接成一个可执行的ELF文件。
- 它是怎么出现内存中的?
- 当我们运行hello程序时,操作系统的加载器会将ELF文件加载到内存中。加载器会解析ELF文件的头部信息,确定程序的入口点、代码段、数据段等信息,并将这些段加载到内存中的相应位置。
- 为什么会出现在目前的内存位置?
- ELF文件中包含了段表和程序头表,这些表格定义了各个段在内存中的位置。加载器根据这些信息将各个段加载到指定的内存地址。例如,代码段通常加载到一个固定的地址(如0x8048000),数据段加载到另一个地址。
- 它的第一条指令在哪里?
- hello程序的第一条指令位于ELF文件的入口点。入口点地址在ELF文件头中指定,通常是程序的
_start函数的地址。加载器在加载完程序后,会将控制权转移到这个入口点,开始执行程序的第一条指令。
- 究竟是怎么执行到它的第一条指令的?
- 加载器将程序加载到内存后,会设置CPU的程序计数器(PC)指向程序的入口点地址。然后,CPU开始从这个地址执行指令,逐条执行程序的代码。
- hello程序在不断地打印字符串, 每一个字符又是经历了什么才会最终出现在终端上?
- hello程序使用
printf函数打印字符串。printf函数会将字符串格式化后,通过系统调用(如write)将字符串写入标准输出(通常是终端)。系统调用会将数据从用户空间传递到内核空间,内核再将数据写入终端设备的缓冲区,最终显示在终端上。
仙剑奇侠传究竟如何运行
- 过程:
应用程序层(仙剑奇侠传)
调用
PAL_SplashScreen函数:
- 仙剑奇侠传的代码调用PAL_SplashScreen函数来播放启动动画。
- 该函数读取mgo.mkf文件中的数据,并将其解码为像素信息。读取文件:
-PAL_SplashScreen函数调用PAL_MKFReadChunk函数来读取mgo.mkf文件中的数据。
-PAL_MKFReadChunk函数通过标准库函数(如fopen、fread等)来读取文件数据。库函数层
标准库函数:
- 标准库函数(如fopen、fread等)被调用来读取文件数据。
- 这些函数最终会调用系统调用接口来执行实际的文件操作。操作系统层(Nanos-lite)
系统调用:
- 标准库函数通过系统调用接口(如SYS_open、SYS_read等)与操作系统交互。
- 这些系统调用由 Nanos-lite 实现。文件系统操作:
- Nanos-lite 的文件系统模块处理这些系统调用,执行实际的文件操作。
- 文件系统模块读取文件数据,并将其返回给应用程序。抽象机器层(AM)
硬件抽象:
- AM 提供硬件抽象层,处理底层硬件操作。
- AM 负责处理内存映射、设备 I/O 等操作。模拟器层(NEMU)
指令模拟:
- NEMU 模拟 CPU 指令执行,处理应用程序和操作系统的指令。
- NEMU 负责模拟内存访问、设备 I/O 等操作。显示更新
解码像素数据:
-PAL_SplashScreen函数解码从mgo.mkf文件中读取的像素数据。
- 解码后的像素数据存储在内存中。更新屏幕:
-PAL_SplashScreen函数调用显示更新函数(如VIDEO_UpdateScreen)来更新屏幕。
- 显示更新函数通过系统调用接口与操作系统交互,执行实际的屏幕更新操作。系统调用和硬件交互
系统调用:
- 显示更新函数通过系统调用接口(如SYS_write)与操作系统交互。
- 操作系统处理这些系统调用,执行实际的屏幕更新操作。硬件交互:
- 操作系统通过 AM 与底层硬件交互,执行屏幕更新操作。
- AM 负责处理内存映射、设备 I/O 等操作,将像素数据写入帧缓冲区。
If you like my blog, you can approve me by scanning the QR code below.

