

PA2 - 简单复杂的机器: 冯诺依曼计算机系统
- 首先切换到pa2分支
- task PA2.1: 实现更多的指令, 在NEMU中运行大部分
cpu-tests - task PA2.2: 实现klib和基础设施
- task PA2.3: 运行FCEUX, 提交完整的实验报告
不停计算的机器
- CPU究竟是怎么执行一条指令的:
- 对于大部分指令来说, 执行它们都可以抽象成取指-译码-执行的指令周期.
- 计算机不断重复下面四个步骤
1.取指(instruction fetch, IF)
- “存储控制,程序控制”——指令在存储器中, 由PC指出当前指令的位置.
- 事实上, PC就是一个指针
- 取指令要做的事情:将PC指向的指令从内存读入到CPU中.
2.译码(instruction decode, ID)
- 取指后发现是个01组成的比特串
- 指令是做什么的:CPU是用来处理数据的, 指令则是用来指示CPU具体对什么数据进行什么样的处理.
- CPU需要从指令中解读出”操作码“和”操作数“两部分信息
- 译码:CPU拿到一条指令之后, 可以通过查表的方式得知这条指令的操作数和操作码.
3.执行(execute, EX)
- 执行阶段就是真正完成指令的工作
4.更新PC
- 执行完一条指令之后, CPU就要执行下一条指令. 在这之前, CPU需要更新PC的值
- 让PC加上刚才执行完的指令的长度, 即可指向下一条指令的位置.
YEMU: 一个简单的CPU模拟器
- 一个简单计算机:
- 有4个8位的寄存器, 一个4位PC, 以及一段16字节的内存.
- 它支持R型和M型两种指令格式, 4条指令.
必做:理解YEMU如何执行程序
1 | YEMU可以看成是一个简化版的NEMU, 它们的原理是相通的, 因此你需要理解YEMU是如何执行程序的. 具体地, 你需要 |
- 画出在YEMU上执行的加法程序的状态机
1 | +---------+ +---------+ +---------+ +---------+ +---------+ |
- 通过RTFSC理解YEMU如何执行一条指令
- 取指
1
this.inst = M[pc]; // 从内存中取出当前PC指向的指令
- 译码
1
switch (this.rtype.op) {...}
- 执行
- 对于操作码0b0000 (复制操作):
1
case 0b0000: { DECODE_R(this); R[rt] = R[rs]; break; }
- 对于操作码0b0001 (加法操作):
1
case 0b0001: { DECODE_R(this); R[rt] += R[rs]; break; }
- 对于操作码0b1110 (从内存加载):
1
case 0b1110: { DECODE_M(this); R[0] = M[addr]; break; }
- 对于操作码0b1111 (存储到内存):
1
case 0b1111: { DECODE_M(this); M[addr] = R[0]; break; }
- 更新PC
1
pc ++; // 更新PC
- 结束
- 如果遇到无效指令:
1
2
3
4default:
printf("Invalid instruction with opcode = %x, halting...\n", this.rtype.op);
halt = 1;
break;
- 两者联系
- 状态机图展示了YEMU执行加法程序的各个阶段,从取指到更新PC,再到结束。
- RTFSC分析展示了这些阶段在代码中的具体实现。
RTFSC(2)
RTFM
- 决定往TRM中添加各种高效指令
- ISA手册(riscv32)中一般都会有以下内容, 尝试RTFM并寻找这些内容的位置:
- 每一条指令具体行为的描述
- 指令opcode的编码表格
- 在PA中, riscv32的客户程序只会由RV32I和RV32M两类指令组成
- 例子:在RISC-V手册中查找加法指令
ADD的具体行为的描述和操作码编码表格- 具体行为的描述
ADD rd, rs1, rs2:将寄存器rs1和rs2的值相加,并将结果存储到寄存器rd中。- 功能:rd = rs1 + rs2
- 操作数:rd、rs1、rs2
- 执行结果:rd中存储相加结果
- 副作用:无
- 操作码编码表格
- 操作码:0b0110011
- 功能码:0b000
- 表格:
1
2
3
4
5+---------+---------+---------+---------+---------+---------+
| funct7 | rs2 | rs1 | funct3 | rd | opcode |
+---------+---------+---------+---------+---------+---------+
| 0000000 | rs2(5) | rs1(5) | 000 | rd(5) | 0110011 |
+---------+---------+---------+---------+---------+---------+
- 具体行为的描述
RTFSC(2)
- 介绍NEMU的框架代码如何实现指令的执行.
NEMU ISA相关的API说明文档
- 全局类型
word_t表示与ISA字长等长的无符号类型, 在32位的ISA中为uint32_tsword_t表示与ISA字长等长的有符号类型, 在32位的ISA中为int32_tchar *FMT_WORDword_t类型对应的十六进制格式化说明符, 在32位的ISA中为”0x%08x”
- Monitor相关
unsigned char isa_logo[];用于在未实现指令的报错信息中提示开发者阅读相关的手册.- ``word_t RESET_VECTOR;`表示PC的初始值.
void init_isa();在monitor初始化时调用, 进行至少如下ISA相关的初始化工作:- 设置必要的寄存器初值, 如PC等
- 加载内置客户程序
- 寄存器相关
struct { // ... word_t pc; } CPU_state;用于存放ISA相关的译码信息, 会嵌入在译码信息结构体Decode的定义中.1
2
3
4
5
6
7
8
9寄存器结构的类型定义, 其中必须包含一个名为pc, 类型为word_t的成员.
- ``CPU_state cpu;``寄存器结构的全局定义.
- ``void isa_reg_display();``打印寄存器当前的值.
- ``word_t isa_reg_str2val(const char *name, bool *success);``若存在名称为name的寄存器, 则返回其当前值, 并设置success为true; 否则设置success为false.
- 指令执行相关
- ```
struct {
// ...
} ISADecodeInfo;int isa_exec_once(Decode *s);取出s->pc指向的指令并译码执行, 同时更新s->snpc.
- 虚拟内存相关
int isa_mmu_check(vaddr_t vaddr, int len, int type);检查当前系统状态下对内存区间为(vaddr, vaddr + len), 类型为type的访问是否需要经过地址转换.paddr_t isa_mmu_translate(vaddr_t vaddr, int len, int type);对内存区间为(vaddr, vaddr + len), 类型为type的内存访问进行地址转换.
- 中断异常相关
vaddr_t isa_raise_intr(word_t NO, vaddr_t epc);抛出一个号码为NO的异常, 其中epc为触发异常的指令PC, 返回异常处理的出口地址.word_t isa_query_intr();查询当前是否有未处理的中断, 若有则返回中断号码, 否则返回INTR_EMPTY.
- DiffTest相关
bool isa_difftest_checkregs(CPU_state *ref_r, vaddr_t pc);检查当前的寄存器状态是否与ref_r相同, 其中pc为cpu.pc的上一条动态指令的PC, 即cpu.pc的旧值. 如果状态相同, 则返回true, 否则返回false.void isa_difftest_attach();将当前的所有状态同步到REF, 并在之后的执行中开启DiffTest.
取指(instruction fetch, IF)
- 在NEMU中, 有一个函数
inst_fetch()(在nemu/include/cpu/ifetch.h中定义)专门负责取指令的工作. inst_fetch()最终会根据参数len来调用vaddr_ifetch()(在nemu/src/memory/vaddr.c中定义), 而目前vaddr_ifetch()又会通过paddr_read()来访问物理内存中的内容.
- 取指操作的本质:一次内存的访存
isa_exec_once()在调用inst_fetch()的时候传入了s->snpc的地址, 因此inst_fetch()最后还会根据len来更新s->snpc, 从而让s->snpc指向下一条指令.
译码(instruction decode, ID)
指令的具体操作
- 代码进入
decode_exec()函数, 它首先进行的是译码相关的操作- 译码的目的是得到指令的操作和操作对象, 这主要是通过查看指令的opcode来决定的
- NEMU的译码方式:模式匹配, NEMU可以通过一个模式字符串来指定指令中opcode
- riscv32中有如下模式:例子(
auipc指令,是将当前PC值与立即数相加并写入寄存器)
1 | INSTPAT_START(); |
- 其中
INSTPAT(意思是instruction pattern)是一个宏(在nemu/include/cpu/decode.h中定义), 它用于定义一条模式匹配规则. 其格式如下:
1 | INSTPAT(模式字符串, 指令名称, 指令类型, 指令执行操作); |
- 模式字符串中只允许出现4种字符:
- 0表示相应的位只能匹配0
- 1表示相应的位只能匹配1
- ?表示相应的位可以匹配0或1
- 空格是分隔符, 只用于提升模式字符串的可读性, 不参与匹配
- 指令名称在代码中仅当注释使用, 不参与宏展开;
- 指令类型用于后续译码过程;
- 指令执行操作则是通过C代码来模拟指令执行的真正行为.
- 此外, nemu/include/cpu/decode.h中还定义了宏INSTPAT_START和INSTPAT_END. INSTPAT又使用了另外两个宏INSTPAT_INST和INSTPAT_MATCH, 它们在nemu/src/isa/$ISA/inst.c中定义.
- 对上述代码进行宏展开并简单整理代码之后, 最后将会得到:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16{ const void * __instpat_end = &&__instpat_end_;
do {
uint64_t key, mask, shift;
pattern_decode("??????? ????? ????? ??? ????? 00101 11", 38, &key, &mask, &shift);
if ((((uint64_t)s->isa.inst >> shift) & mask) == key) {
{
int rd = 0;
word_t src1 = 0, src2 = 0, imm = 0;
decode_operand(s, &rd, &src1, &src2, &imm, TYPE_U);
R(rd) = s->pc + imm;
}
goto *(__instpat_end);
}
} while (0);
// ...
__instpat_end_: ; }- 上述代码中的&&__instpat_end_使用了GCC提供的标签地址扩展功能, goto语句将会跳转到最后的__instpat_end_标签.
pattern_decode()函数在nemu/include/cpu/decode.h中定义, 它用于将模式字符串转换成3个整型变量pattern_decode()函数将模式字符串中的0和1抽取到整型变量key中,mask表示key的掩码, 而shift则表示opcode距离最低位的比特数量, 用于帮助编译器进行优化.
- NEMU取指令的时候会把指令记录到
s->isa.inst中, 此时指令满足上述宏展开的if语句, 表示匹配到auipc指令的编码, 因此将会进行进一步的译码操作.
指令的操作对象
- eg:已知
auipc是将当前PC值与立即数相加并写入寄存器, 但我们还是不知道操作对象(比如立即数是多少, 写入到哪个寄存器).- 调用
decode_operand()函数来完成
- 调用
decode_operand()函数- 会根据传入的指令类型type来进行操作数的译码,
- 译码结果将记录到函数参数rd, src1, src2和imm中, 它们分别代表目的操作数的寄存器号码, 两个源操作数和立即数.
- 为了进一步实现操作数译码和指令译码的解耦, 我们对这些操作数的译码进行了抽象封装:
- 框架代码定义了
src1R()和src2R()两个辅助宏, 用于寄存器的读取结果记录到相应的操作数变量中 - 框架代码还定义了
immI等辅助宏, 用于从指令中抽取出立即数
- 框架代码定义了
- 例如RISC-V中I型指令的译码过程可以通过如下代码实现:
1
case TYPE_I: src1R(); immI(); break;
立即数背后的故事
- Motorola 68k系列的处理器都是大端架构的. 现在问题来了, 考虑以下两种情况:
- 假设我们需要将NEMU运行在Motorola 68k的机器上(把NEMU的源代码编译成Motorola 68k的机器码)
- 假设我们需要把Motorola 68k作为一个新的ISA加入到NEMU中
在这两种情况下, 你需要注意些什么问题? 为什么会产生这些问题? 怎么解决它们?
事实上不仅仅是立即数的访问, 长度大于1字节的内存访问都需要考虑类似的问题.
- 情况1:将NEMU运行在Motorola 68k的机器上
- 问题
- 字节序问题
- Motorola 68k是大端架构,而NEMU可能是为小端架构设计的。
- 需要确保数据在内存中的存储顺序正确。
- 编译器和工具链
- 需要使用支持Motorola 68k架构的编译器和工具链。
- 可能需要修改Makefile或构建脚本以适应新的编译环境。
- 系统调用和库函数
- 需要确保NEMU使用的系统调用和库函数在Motorola 68k平台上可用。
- 可能需要对代码进行移植和适配。
- 字节序问题
- 解决方案
- 字节序处理
- 使用条件编译或宏定义来处理大端和小端的差异。
- 例如:
1
2
3
4
5
// 大端处理代码
// 小端处理代码 - 编译器和工具链
- 安装并配置支持Motorola 68k的编译器和工具链。
- 修改构建脚本以使用新的编译器。
- 系统调用和库函数
- 检查并移植系统调用和库函数,确保它们在Motorola 68k平台上正常工作。
- 字节序处理
- 问题
- 情况 2: 将Motorola 68k作为一个新的ISA加入到NEMU中
- 问题+解决方案
- 指令集架构 (ISA) 支持
- 需要在NEMU中添加对Motorola 68k指令集的支持。
- 包括指令的译码、执行和模拟。
- 寄存器和内存模型
- 需要定义Motorola 68k的寄存器和内存模型。
- 确保模拟器能够正确处理寄存器和内存操作。
- 异常和中断处理
- 需要实现Motorola 68k的异常和中断处理机制。
- 确保模拟器能够正确模拟这些行为。
- 指令集架构 (ISA) 支持
- 问题+解决方案
立即数背后的故事(2)
- mips32和riscv32的指令长度只有32位, 因此它们不能像x86那样, 把C代码中的32位常数直接编码到一条指令中. 思考一下, mips32和riscv32应该如何解决这个问题?
- MIPS32和RISC-V32通过组合使用两条指令和伪指令
li来加载32位立即数。
- MIPS32和RISC-V32通过组合使用两条指令和伪指令
执行(execute, EX)
- 模式匹配规则中指定的
指令执行操作 - 译码的结果+C代码——模拟指令执行的真正行为
- eg:如对于auipc指令
- 由于
译码阶段已经把U型立即数记录到操作数imm中了 - 只需要通过
R(rd) = s->pc + imm将立即数与当前PC值相加并写入目标寄存器中, 这样就完成了指令的执行.
- 由于
- 指令执行的阶段结束之后,
decode_exec()函数将会返回0, 并一路返回到exec_once()函数中. 不过目前代码并没有使用这个返回值, 因此可以忽略它
更新PC
- 更新PC:把
s->dnpc赋值给cpu.pc
静态指令snpc和动态指令dnpc
- 在程序分析领域中, 静态指令是指程序代码中的指令, 动态指令是指程序运行过程中的指令. 例如对于以下指令序列
1 | 100: jmp 102 |
- jmp指令的下一条静态指令是add指令, 而下一条动态指令则是xor指令.
- snpc和dnpc的区别: snpc是下一条静态指令, 而dnpc是下一条动态指令
- 对于顺序执行的指令, 它们的snpc和dnpc是一样的;
- 对于跳转指令, snpc和dnpc就会有所不同, dnpc应该指向跳转目标的指令.
- 显然, 我们应该使用s->dnpc来更新PC, 并且在指令执行的过程中正确地维护s->dnpc.
结构化程序设计
- 如果指令集越复杂, 指令之间的共性特征就越多——Copy-Paste的话,维护难度很大!
- 对于同一条指令的不同形式, 它们的执行阶段是相同的
- 对于不同指令的同一种形式, 它们的译码阶段是相同的
- 对于同一条指令同一种形式的不同操作数宽度
- 一种好的做法是把译码, 执行和操作数宽度的相关代码分离开来, 实现解耦, 也就是在程序设计课上提到的结构化程序设计.
必做:RTFSC理解指令执行的过程
- 请整理一条指令在NEMU中的执行过程
- 取指
- 从内存中取出当前PC指向的指令
- 更新PC,指向下一条指令
cpu.pc += 4;
- 译码
- 解析指令的操作码&操作数
- 根据指令类型和操作数,确定指令的具体操作
- 执行
- 根据译码结果执行指令的具体操作
- 对于算术运算指令,执行相应的算术运算
- 对于跳转指令。计算跳转目标地址
- 根据译码结果执行指令的具体操作
- 访存
- 如果指令需要访问内存(加载/存储指令)
- 写回
- 将执行结果写回寄存器或内存
- 更新PC
- 在指令执行完毕后,根据指令的类型和执行结果更新PC。
- 对于顺序执行的指令,PC已经在取指阶段更新过了,这里不需要再次更新。
- 对于跳转指令,PC需要更新为跳转目标地址。
1
cpu.pc = s->dnpc; // 将dnpc的值赋给cpu.pc,更新PC
运行第一个C程序
- 开始实践啦!
必做:准备交叉编译环境
- 准备相应的gcc和binutils, 才能正确地进行编译
- riscv32(64)
apt-get install g++-riscv64-linux-gnu binutils-riscv64-linux-gnu
- 报错
/usr/riscv64-linux-gnu/include/gnu/stubs.h:8:11: fatal error: gnu/stubs-ilp32.h: No such file or directory - 键入
sudo code --no-sandbox --user-data-dir=/home/xiaoyao/.vscode-root /usr/riscv64-linux-gnu/include/gnu/stubs.h - 修改
1 |
|
- 报错
1 | + OBJCOPY -> build/dummy-riscv32-nemu.bin |
- 检查python3已安装,则创建python命令的符号链接
sudo ln -s /usr/bin/python3 /usr/bin/pythonpython --version确保可用后,重新运行
- 输入
c,报错- 这是因为你还没有实现
0x00000413的指令, 因此, 你需要开始在NEMU中添加指令了.
- 这是因为你还没有实现
为什么执行了未实现指令会出现上述报错信息
RTFSC, 理解执行未实现指令的时候, NEMU具体会怎么做.
因为NEMU在执行指令时,会检查指令是否已实现。如果指令未实现,NEMU会触发异常并输出错误信息。
查看反汇编结果
am-kernels/tests/cpu-tests/build/dummy-$ISA-nemu.txt- 你只需实现那些目前还没实现的指令
- 为了实现一条新指令, 你只需要在
nemu/src/isa/$ISA/inst.c中添加正确的模式匹配规则即可
必做:运行第一个客户程序
- 在NEMU中实现上文提到的指令, 具体细节请务必参考手册. 实现成功后, 在NEMU中运行客户程序dummy, 你将会看到HIT GOOD TRAP的信息. 如果你没有看到这一信息, 说明你的指令实现不正确, 你可以使用PA1中实现的简易调试器帮助你调试.
- li是一个伪指令,在riscv32里面汇编器会将它替换为lui和/或addi
- 根据func3字段判断,这里其实是要实现addi指令
1 | INSTPAT("??????? ????? ????? ??? ????? 00100 11", li , I, R(rd) = imm); |
- jal
- 添加TYPE_J
#define immJ() do { *imm = (SEXT(BITS(i, 31, 31), 1) << 20) | BITS(i, 30, 21) << 1| BITS(i, 20, 20) << 11 | BITS(i, 19, 12) << 12 ; } while(0)case TYPE_J: immJ(); break; // 新增 J 类型
1 | INSTPAT("??????? ????? ????? ??? ????? 11011 11", jal , J, R(rd) = s -> pc + 4; s -> dnpc += imm -4;); // jal指令 |
- sw
1 | INSTPAT("??????? ????? ????? 010 ????? 01000 11", sw , S, Mw(src1 + imm, 4, src2)); // 新增 sw 指令 |
src/cpu/cpu-exec.c:126 cpu_exec] nemu: HIT GOOD TRAP at pc = 0x80000030成功!
运行更多的程序
- 测试用例:
am-kernels/tests/cpu-tests/- 在该目录下执行
make ARCH=$ISA-nemu ALL=xxx run- 其中xxx为测试用例的名称(不包含.c后缀).
- 在该目录下执行
必做:实现更多的指令
1. add.c
- lw
0x80000078: 00 0a a9 03 lw s2, 0(s5)
INSTPAT("??????? ????? ????? 010 ????? 00000 11", lw , I, R(rd) = Mr(src1 + imm, 4));
- add
0x80000090: 00 a9 05 33 add a0, s2, a0
INSTPAT("0000000 ????? ????? 000 ????? 01100 11", add , R, R(rd) = src1 + src2);
- sub
0x80000094: 40 f5 05 33 sub a0, a0, a5
INSTPAT("0100000 ????? ????? 000 ????? 01100 11", sub , R, R(rd) = src1 - src2);
- seqz:
0x80000098: 00 15 35 13 seqz a0, a0- 此伪指令的实现原理为,使用SLTIU指令,并将立即数设置为1;此时只有当rs1寄存器值为0时,才能小于立即数,rd寄存器才会被赋值为1:
INSTPAT("??????? ????? ????? 011 ????? 00100 11", seqz , I, R(rd) = (uint32_t)src1 < (uint32_t)imm ? 1: 0);
- beqz:
0x80000010: 00 05 04 63 beqz a0, 8- 伪指令,可用beq指令来实现
INSTPAT("??????? ????? ????? 000 ????? 11000 11", beqz , B, if (src1 == src2) s->dnpc = s->pc + imm);#define immB() do { *imm = (SEXT(BITS(i, 31, 31), 1) << 12) | (BITS(i, 7, 7) << 11) | (BITS(i, 30, 25) << 5) | (BITS(i, 11, 8) << 1); } while(0)
- bne:
0x800000a4: fe 89 90 e3 bne s3, s0, -0x20INSTPAT("??????? ????? ????? 001 ????? 11000 11", bne , B, if (src1 != src2) s->dnpc = s->pc + imm);- bne,比较两个寄存器的值,如果它们不相等,则跳转到目标地址
HIT GOOD TRAP at pc = 0x80000120,add.c成功!
2. add—longlong.c
- sltu:
0x800000a0: 01 97 b6 b3 sltu a3, a5, s9INSTPAT("0000000 ????? ????? 011 ????? 01100 11", sltu , R, R(rd) = (uint32_t)src1 < (uint32_t)src2 ? 1: 0);- sltu,无符号比较两个寄存器的值,如果第一个寄存器的值小于第二个,则将目标寄存器设置为 1,否则设置为 0
- xor:
0x800000ac: 00 f5 45 33 xor a0, a0, a5INSTPAT("0000000 ????? ????? 100 ????? 01100 11", xor , R, R(rd) = src1 ^ src2);- xor,异或运算,将两个寄存器的值进行异或运算,结果存入目标寄存器
- or:
0x800000b4: 00 f5 65 33 or a0, a0, a5INSTPAT("0000000 ????? ????? 110 ????? 01100 11", or , R, R(rd) = src1 | src2);- or,或运算,将两个寄存器的值进行或运算,结果存入目标寄存器
HIT GOOD TRAP at pc = 0x80000138,成功!
3. bit.c
- sh:
0x800000bc: 00 f1 16 23 sh a5, 0xc(sp)INSTPAT("??????? ????? ????? 001 ????? 01000 11", sh , S, Mw(src1 + imm, 2, src2));- sh,将src2的低16位存入src1+imm地址
- srai:
0x80000028: 40 35 d7 93 srai a5, a1, 3INSTPAT("0100000 ????? ????? 101 ????? 00100 11", srai , I, R(rd) = (int32_t)src1 >> (imm & 0x1F));- srai,算术右移,将src1的值右移imm位,空位用src1的符号位填充,结果存入rd
- andi:
0x80000034: 00 75 f5 93 andi a1, a1, 7INSTPAT("??????? ????? ????? 111 ????? 00100 11", andi , I, R(rd) = src1 & imm);- andi,与立即数,将src1的值与imm进行与运算,结果存入rd
- sll:
0x8000003c: 00 b7 97 b3 sll a5, a5, a1INSTPAT("0000000 ????? ????? 001 ????? 01100 11", sll , R, R(rd) = src1 << (src2 & 0x1F));- sll,逻辑左移,将src1的值左移src2位,空位用0填充,结果存入rd
- and:
INSTPAT("0000000 ????? ????? 111 ????? 01100 11", and , R, R(rd) = src1 & src2);- and,与运算,将src1的值与src2的值进行与运算,结果存入rd
- xori:
INSTPAT("??????? ????? ????? 100 ????? 00100 11", xori , I, R(rd) = src1 ^ imm);- xori,异或立即数,将src1的值与imm进行异或运算,结果存入rd
HIT GOOD TRAP at pc = 0x8000021c成功!
4. bubble-sort.c
- blez:
0x80000040: 02 b0 50 63 blez a1, 0x20INSTPAT("??????? ????? ????? 101 ????? 11000 11", blez , B, if (src1 >= src2) s->dnpc +=imm-4);- blez,伪指令可用bgz,当寄存器的值小于等于0时跳转,可用bgez指令实现
HIT GOOD TRAP at pc = 0x80000140成功!
5. crc32.c
- 看
tests/cpu-tests/build/crc32-riscv32-nemu.txt
- lui:
0x80000038: ed b8 88 b7 lui a7, 0xedb88INSTPAT("??????? ????? ????? ??? ????? 01101 11", lui , U, R(rd) = imm);- lui,将imm的值左移12位存入rd
- srli:
0x8000005c: 00 17 d7 93 srli a5, a5, 1INSTPAT("0000000 ????? ????? 101 ????? 00100 11", srli , I, R(rd) = (uint32_t)src1 >> (imm & 0x1F));- srli,逻辑右移,将src1的值右移imm位,空位用0填充,结果存入rd
- bgeu:
8000008c: 02c5fc63 bgeu a1,a2,800000c4 <rc_crc32+0x9c>INSTPAT("??????? ????? ????? 111 ????? 11000 11", bgeu , B, if ((uint32_t)src1 >= (uint32_t)src2) s->dnpc = s->pc + imm);- bgeu,无符号比较两个寄存器的值,如果第一个寄存器的值大于等于第二个,则跳转到目标地址
- slli:
800000a8: 00279793 slli a5,a5,0x2INSTPAT("0000000 ????? ????? 001 ????? 00100 11", slli , I, R(rd) = src1 << (imm & 0x1F));
- slli,逻辑左移,将src1的值左移imm位,空位用0填充,结果存入rd
HIT GOOD TRAP at pc = 0x8000012c成功!
6. div.c
tests/cpu-tests/build/div-riscv32-nemu.txt
- mul:
8000007c: 02f70733 mul a4,a4,a5INSTPAT("0000001 ????? ????? 000 ????? 01100 11", mul , R, R(rd) = src1 * src2);
- div:
800000a8: 02f74733 div a4,a4,a5INSTPAT("0000001 ????? ????? 100 ????? 01100 11", div , R, R(rd) = (int32_t)src1 / (int32_t)src2);
HIT GOOD TRAP at pc = 0x80000124成功!
7. fact.c+fib.c
- 直接
HIT GOOD TRAP了
8. goldbach.c
- rem:
8000007c: 02f666b3 rem a3,a2,a5INSTPAT("0000001 ????? ????? 110 ????? 01100 11", rem , R, R(rd) = (int32_t)src1 % (int32_t)src2);- 求余
HIT GOOD TRAP at pc = 0x80000118成功
9. if-else.c
- blt:
80000080: 02f94063 blt s2,a5,800000a0 <main+0x78>INSTPAT("??????? ????? ????? 100 ????? 11000 11", blt , B, if ((int32_t)src1 <(int32_t)src2) s->dnpc += imm-4);- blt,比较两个寄存器的值,如果第一个小于第二个,则跳转到目标地址
- slt:
80000084: 00fa2733 slt a4,s4,a5INSTPAT("0000000 ????? ????? 010 ????? 01100 11", slt , R, R(rd) = (int32_t)src1 < (int32_t)src2 ? 1 : 0);- slt,有符号比较两个寄存器的值,如果第一个寄存器的值小于第二个,则将目标寄存器设置为 1,否则设置为 0
HIT GOOD TRAP at pc = 0x80000110成功!
10. leap-year.c+load-store.c
HIT GOOD TRAP at pc = 0x800000dc
- lh:
80000064: 00049503 lh a0,0(s1)INSTPAT("??????? ????? ????? 001 ????? 00000 11", lh , I, R(rd) = SEXT(Mr(src1 + imm, 2), 16));- lh,将src1+imm地址的值的低16位存入rd
- lhu:
8000008c: 00045503 lhu a0,0(s0)INSTPAT("??????? ????? ????? 101 ????? 00000 11", lhu , I, R(rd) = Mr(src1 + imm, 2));- lhu,将src1+imm地址的值存入rd
HIT GOOD TRAP at pc = 0x800001ec
11. matrix-mul.c+max.c
HIT GOOD TRAP at pc = 0x8000015c- 出错:
0x8000008c: 01 25 54 63 bge a0, s2, 8 - bge:
INSTPAT("??????? ????? ????? 101 ????? 11000 11", blez , B, if ((int)src1 >= (int)src2) s->dnpc +=imm-4);- 无符号改成有符号(加上(int))!
HIT GOOD TRAP at pc = 0x80000124
12. mersenne.c
- mulh:
80000098: 02f795b3 mulh a1,a5,a5INSTPAT("0000001 ????? ????? 001 ????? 01100 11", mulh , R, R(rd) = ((int64_t)src1 * (int64_t)src2) >> 32);
- remu:
8000018c: 02c577b3 remu a5,a0,a2INSTPAT("0000001 ????? ????? 111 ????? 01100 11", remu , R, R(rd) = (uint32_t)src1 % (uint32_t)src2);- remu,无符号数,求余数
- divu:
80000198: 03695533 divu a0,s2,s6INSTPAT("0000001 ????? ????? 101 ????? 01100 11", divu , R, R(rd) = (uint32_t)src1 / (uint32_t)src2);
HIT GOOD TRAP at pc = 0x80000144
13. min3.c+mov-c.c+movsx.c+mul-longlong.c
HIT GOOD TRAP at pc = 0x80000170HIT GOOD TRAP at pc = 0x80000124HIT GOOD TRAP at pc = 0x800001d0HIT BAD TRAP at pc = 0x80000140!!- mul有问题,改:
INSTPAT("0000001 ????? ????? 001 ????? 01100 11", mulh , R, int32_t a1 = src1; int32_t a2 = src2; int64_t tmp = (int64_t)a1 * (int64_t)a2; R(rd) = BITS(tmp, 63, 32)); - 为什么原方法不对:
- 符号扩展问题:
- src1 和 src2 被直接转换为 int64_t 类型。如果 src1 和 src2 是负数,符号扩展可能会导致错误的结果。
- 通过将 src1 和 src2 显式转换为 int32_t 类型,然后再转换为 int64_t 类型,确保了符号扩展的正确性。
- 位移操作的行为:
- 若乘积直接右移 32 位。如果乘积是负数,右移操作可能会保留符号位,导致错误的结果。
- 而通过使用 BITS 宏提取特定位数,确保了结果的正确性。
- 符号扩展问题:
14. pascal.c + prime.c + quick-sort.c + recursion.c + select-sort.c + shuixianhua.c
HIT GOOD TRAP at pc = 0x80000128HIT GOOD TRAP at pc = 0x800000dcHIT GOOD TRAP at pc = 0x800003ccHIT GOOD TRAP at pc = 0x8000026cHIT GOOD TRAP at pc = 0x8000015cHIT GOOD TRAP at pc = 0x8000011c
15. shift.c
- sra:
800000a8: 40855533 sra a0,a0,s0INSTPAT("0100000 ????? ????? 101 ????? 01100 11", sra , R, R(rd) = (int32_t)src1 >> (src2 & 0x1F));- sra,算术右移,将src1的值右移src2位,空位用src1的符号位填充,结果存入rd
- srl:
800000e0: 00855533 srl a0,a0,s0INSTPAT("0000000 ????? ????? 101 ????? 01100 11", srl , R, R(rd) = (uint32_t)src1 >> (src2 & 0x1F));- srl,逻辑右移,将src1的值右移src2位,空位用0填充,结果存入rd
HIT GOOD TRAP at pc = 0x80000144
16. sub-longlong.c + sum.c + switch.c + to-lower-case.c + unalign.c + wanshu.c
HIT GOOD TRAP at pc = 0x80000138HIT GOOD TRAP at pc = 0x8000009c
- bltu:
80000070: 009a6463 bltu s4,s1,80000078 <main+0x50>INSTPAT("??????? ????? ????? 110 ????? 11000 11", bltu , B, if ((uint32_t)src1 < (uint32_t)src2) s->dnpc = s->pc + imm);- bltu,无符号比较两个寄存器的值,如果第一个寄存器的值小于第二个,则跳转到目标地址
HIT GOOD TRAP at pc = 0x800000e8HIT GOOD TRAP at pc = 0x800000d4HIT GOOD TRAP at pc = 0x80000144HIT GOOD TRAP at pc = 0x80000104
ps:hello-str.c和string.c
- 还需要实现额外的内容才能运行(具体在后续小节介绍), 目前可以先使用其它测试用例进行测试.
mips32的分支延迟槽
- 为了提升处理器的性能, mips使用了一种叫分支延迟槽的技术。
- 程序的执行顺序发生一些改变:
- 把紧跟在跳转指令(包括有条件和无条件)之后的静态指令称为延迟槽
- 那么程序在执行完跳转指令后, 会先执行延迟槽中的指令, 再执行位于跳转目标的指令。
- 延迟槽技术需要软硬件协同才能正确工作: mips手册中描述了这一约定, 处理器设计者按照这一约定设计处理器, 而编译器开发者则会让编译器负责在延迟槽中放置一条有意义的指令, 使得无论是否跳转, 按照这一约定的执行顺序都能得到正确的执行结果.
- 如果你是编译器开发者, 你将会如何寻找合适的指令放到延迟槽中呢?
- 尽量选择不会影响程序逻辑的无副作用的指令
- 选择与跳转指令无关的独立的指令,即不依赖于跳转指令的结果,也不影响跳转目标的执行。
- 将原本在跳转目标处执行的指令提前到延迟槽中执行,可以减少跳转目标处的指令数量,提升性能
指令名对照
- AT&T格式反汇编结果中的少量指令, 与手册中列出的指令名称不符, 如x86的cltd, mips32和riscv32则有不少伪指令(pseudo instruction). 除了STFW之外, 你有办法在手册中找到对应的指令吗? 如果有的话, 为什么这个办法是有效的呢?
- 办法:
- 获取指令的机器码
- 使用反汇编工具获取指令的机器码。
- 查找操作码和功能码
- 从机器码中提取操作码和功能码。
- 对于RISC-V指令,可以提取操作码(opcode)、功能码(funct3)和功能码(funct7)。
- 查阅手册
- 然后在指令手册中查找对应的操作码和功能码。
- 为什么有效:
- 唯一性:每条指令在机器码级别都有唯一的编码,通过操作码和功能码可以唯一确定一条指令。
- 标准化:指令手册中提供了详细的指令编码表和描述,通过这些表可以准确地找到指令的定义。
- 准确性:相比于直接搜索指令名称,通过操作码和功能码查找指令可以避免名称不一致的问题,确保查找结果的准确性。
PA2.1结束
程序, 运行时环境与AM
运行时环境
- “并不是每一个程序都可以在NEMU中运行”背后的缘由:
- 应用程序的运行都需要运行时环境的支持, 包括加载, 销毁程序, 以及提供程序运行时的各种动态链接库(你经常使用的库函数就是运行时环境提供的)等
- 要提供相应的运行时环境的支持了!
- 为了运行最简单的程序, 我们需要提供什么呢? 其实答案已经在PA1中了:
- 只要把程序放在正确的内存位置, 然后让PC指向第一条指令, 计算机就会自动执行这个程序, 永不停止.
- so:只要有内存, 有结束运行的方式, 加上实现正确的指令, 就可以支撑最简单程序的运行了
将运行时环境封装成库函数
- 我们只需要定义一个结束程序的API, 比如
void halt(), 它对不同架构上程序的不同结束方式进行了抽象: 程序只要调用halt()就可以结束运行, 而不需要关心自己运行在哪一个架构上. - 运行时环境的一种普遍的存在方式: 库
- 通过库, 运行程序所需要的公共要素被抽象成API, 不同的架构只需要实现这些API, 也就相当于实现了支撑程序运行的运行时环境, 这提升了程序开发的效率: 需要的时候只要调用这些API, 就能使用运行时环境提供的相应功能.
思考:这又能怎么样呢
- 思考一下, 这样的抽象还会带来哪些好处呢? 你很快就会体会到这些好处了.
- 代码复用
- 通过定义统一的API,可以在不同的架构上复用相同的程序代码。只需要为每个架构实现对应的API,而不需要为每个程序和每个架构分别编写代码。
- 简化维护
- 维护n个程序和m个架构相关的API实现,只需要维护n+m份代码,而不是n*m份代码。
- 提高开发效率
- 只需要关注程序逻辑,而不需要关心底层架构的具体实现。
- 增强了程序的可移植性
AM - 裸机(bare-metal)运行时环境
- 只进行纯粹计算任务的程序在TRM上就可以运行, 更复杂的应用程序对运行时环境必定还有其它的需求
- eg:超级玛丽需要和用户进行交互
- 如果我们把这些需求都收集起来, 将它们抽象成统一的API提供给程序, 这样我们就得到了一个可以支撑各种程序运行在各种架构上的库了!
- 每个架构都按照它们的特性实现这组API
- 应用程序只需要直接调用这组API即可, 无需关心自己将来运行在哪个架构上.
- 这组API被称为抽象计算机,即AM(Abstract machine)
- AM根据程序的需求把库划分成以下模块:
1
AM = TRM + IOE + CTE + VME + MPE
- TRM(Turing Machine) - 图灵机, 最简单的运行时环境, 为程序提供基本的计算能力
- IOE(I/O Extension) - 输入输出扩展, 为程序提供输出输入的能力
- CTE(Context Extension) - 上下文扩展, 为程序提供上下文管理的能力
- VME(Virtual Memory Extension) - 虚存扩展, 为程序提供虚存管理的能力
- MPE(Multi-Processor Extension) - 多处理器扩展, 为程序提供多处理器通信的能力 (MPE超出了ICS课程的范围, 在PA中不会涉及)
1 | (在NEMU中)实现硬件功能 -> (在AM中)提供运行时环境 -> (在APP层)运行程序 |
思考:为什么要有AM? (建议二周目思考)
- 操作系统也有自己的运行时环境. AM和操作系统提供的运行时环境有什么不同呢? 为什么会有这些不同?
- 不同:
- 抽象层次:
- AM:主要关注于硬件抽象,提供基本的硬件功能抽象,如上下文管理、虚存管理、多处理器通信等。它直接运行在硬件之上,提供一个简化的、统一的硬件接口。
- 操作系统:提供更高层次的抽象,包括进程管理、文件系统、网络通信、安全机制等。操作系统不仅抽象硬件,还管理系统资源,提供丰富的系统服务。
- 功能范围
- AM:功能相对简单,主要提供硬件抽象和基本的运行时环境。
- 操作系统:功能丰富,提供全面的系统服务和资源管理,包括内存管理、进程调度、文件系统、网络堆栈等。
- 目标和用途
- AM:主要用于简化应用程序的开发和移植,使得应用程序可以在不同的硬件平台上运行。它通常用于嵌入式系统、模拟器和教学环境中。
- 操作系统:主要用于管理计算机系统的资源,提供稳定和高效的运行环境。它用于通用计算平台,如桌面计算机、服务器和移动设备。
- 抽象层次:
- 为什么会有这些不同:
- 设计目标
- AM:设计目标是提供一个统一的硬件抽象层,简化应用程序的开发和移植。因此,它的功能范围相对简单,主要关注于硬件抽象。
- 操作系统:设计目标是管理系统资源,提供丰富的系统服务,确保系统的稳定性和高效性。因此,它的功能范围广泛,涉及资源管理和系统服务。
- 复杂性和性能要求
- AM:由于功能简单,AM的实现相对简单,性能开销较小。它适用于对性能要求高、资源有限的环境。
- 操作系统:由于功能丰富,操作系统的实现复杂,性能开销较大。它适用于通用计算平台,提供全面的系统服务。
- 应用场景不同
- AM:适用于嵌入式系统、模拟器和教学环境,提供一个简化的硬件抽象层,方便应用程序的开发和移植。
- 操作系统:适用于通用计算平台,提供全面的系统服务和资源管理,确保系统的稳定性和高效性。
- 设计目标
RTFSC(3)
- AM的子项目
abstract-machine - 整个AM项目分为两大部分:
abstract-machine/am/- 不同架构的AM API实现, 目前我们只需要关注NEMU相关的内容即可. 此外, abstract-machine/am/include/am.h列出了AM中的所有API, 我们会在后续逐一介绍它们.abstract-machine/klib/- 一些架构无关的库函数, 方便应用程序的开发
- TRM的API:
Area heap结构用于指示堆区的起始和末尾void putch(char ch)用于输出一个字符void halt(int code)用于结束程序的运行void _trm_init()用于进行TRM相关的初始化工作
- 堆区是给程序自由使用的一段内存区间, 为程序提供动态分配内存的功能.
halt()里面调用了nemu_trap()宏 (在abstract-machine/am/src/platform/nemu/include/nemu.h中定义), 这个宏展开之后是一条内联汇编语句. 内联汇编语句允许我们在C代码中嵌入汇编语句, 以riscv32为例, 宏展开之后将会得到:asm volatile("mv a0, %0; ebreak" : :"r"(code));- 正是那条特殊的
nemu_trap
- 正是那条特殊的
am-kernels子项目用于收录一些可以在AM上运行的测试集和简单程序- 在让NEMU运行客户程序之前, 我们需要将客户程序的代码编译成可执行文件
- 不能使用gcc的默认选项直接编译
- 默认选项会根据GNU/Linux的运行时环境将代码编译成运行在GNU/Linux下的可执行文件,但此时的NEMU并不能为客户程序提供GNU/Linux的运行时环境
- 使用交叉编译
- 需要在GNU/Linux下根据AM的运行时环境编译出能够在
$ISA-nemu这个新环境中运行的可执行文件 - 为了不让链接器ld使用默认的方式链接, 我们还需要提供描述
$ISA-nemu的运行时环境的链接脚本
- 需要在GNU/Linux下根据AM的运行时环境编译出能够在
- 不能使用gcc的默认选项直接编译
- 交叉编译生成一个可以在NEMU的运行时环境上运行的程序的过程大致如下:
- gcc将
$ISA-nemu的AM实现源文件编译成目标文件, 然后通过ar将这些目标文件作为一个库, 打包成一个归档文件abstract-machine/am/build/am-$ISA-nemu.a - gcc把应用程序源文件(如
am-kernels/tests/cpu-tests/tests/dummy.c)编译成目标文件 - 通过gcc和ar把程序依赖的运行库(如
abstract-machine/klib/)也编译并打包成归档文件 - 根据Makefile文件
abstract-machine/scripts/$ISA-nemu.mk中的指示, 让ld根据链接脚本abstract-machine/scripts/linker.ld, 将上述目标文件和归档文件链接成可执行文件
- gcc将
- 对编译得到的可执行文件的行为进行简单的梳理:
- 第一条指令从
abstract-machine/am/src/$ISA/nemu/start.S开始, 设置好栈顶之后就跳转到abstract-machine/am/src/platform/nemu/trm.c的_trm_init()函数处执行. - 在
_trm_init()中调用main()函数执行程序的主体功能, main()函数还带一个参数, 目前我们暂时不会用到, 后面我们再介绍它. - 从main()函数返回后, 调用
halt()结束运行.
- 第一条指令从
必做:阅读Makefile
abstract-machine项目的Makefile设计得非常巧妙, 你需要把它们看成一种代码来RTFSC, 从而理解它们是如何工作的. 这样一来, 你就知道怎么编写有一定质量的Makefile了; 同时, 如果哪天Makefile出现了非预期的行为, 你就可以尝试对Makefile进行调试了. 当然, 这少不了RTFM.
- 基本设置和检查
- 默认目标:如果没有指定目标,默认构建
image。 - 环境变量检查:确保
$AM_HOME和$ARCH环境变量设置正确。 - 提取架构和平台:从
$ARCH中提取指令集架构(ISA)和平台。 - 检查源文件:确保有源文件可供构建。
- 默认目标:如果没有指定目标,默认构建
- 通用编译目标
- 创建目标目录:在
build/$ARCH目录下创建构建输出目录。 - 编译目标:定义生成的二进制镜像或归档文件的路径。
- 收集链接文件:收集所有需要链接的对象文件和库文件。
- 创建目标目录:在
- 通用编译标志
- 编译器和工具链:定义交叉编译工具链的路径。
- 编译标志:设置编译标志,包括包含路径、架构定义和优化选项。
- 架构特定配置
- 包含架构特定配置:从
scripts/$(ARCH).mk文件中包含架构特定的配置。
- 包含架构特定配置:从
- 编译规则
- 编译规则:定义如何从
.c、.cc、.cpp和.S文件生成对象文件。 - 递归构建库:递归调用 Makefile 构建依赖库。
- 链接规则:定义如何从对象文件和库文件生成最终的 ELF 二进制文件。
- 归档规则:定义如何从对象文件生成归档文件(
.a)。 - 依赖文件:包含由 gcc 生成的依赖文件(
.d)。
- 编译规则:定义如何从
- 杂项
- 构建顺序控制:定义构建顺序,确保依赖关系正确。
- 清理规则:定义清理单个项目和所有子项目的规则。
必做:通过批处理模式运行NEMU
1 | 我们知道, 大部分同学很可能会这么想: 反正我不阅读Makefile, 老师助教也不知道, 总觉得不看也无所谓. |
- 看nemu的代码:
1
2
3
4
5
6
7
8void sdb_mainloop(){
//检查是否处于批处理模式
if(is_batch_mode){
cmd_c(NULL);
return;
}
......//其它代码
}- 进入sdb循环前要进行
is_batch_mode的判断,为true,就会自动执行cmd_c函数,且不会进入sdb循环
- 进入sdb循环前要进行
- 所以使
is_batch_mode=true,而nemu提供了sdb_set_batch_mode()函数,应该调用它。
1 | case 'b':sdb_set_batch_mode();break; |
- 所以:在运行NEMU时传入参数b即可。
- 添加
NEMUFLAGS += -b -l $(shell dirname $(IMAGE).elf)/nemu-log.txt
1 | ### Compilation flags |
实现常用的库函数
- 把运行时环境分成两部分:
- 一部分是架构相关的运行时环境, 也就是我们之前介绍的AM
- 另一部分是架构无关的运行时环境, 类似
memcpy()这种常用的函数应该归入这部分,abstract-machine/klib/用于收录这些架构无关的库函数.klib是kernel library的意思, 用于提供一些兼容libc的基础功能.
- 框架代码在
abstract-machine/klib/src/string.c和abstract-machine/klib/src/stdio.c中列出了将来可能会用到的库函数, 但并没有提供相应的实现.
必做:实现字符串处理函数
- 根据需要实现
abstract-machine/klib/src/string.c中列出的字符串处理函数, 让cpu-tests中的测试用例string可以成功运行. 关于这些库函数的具体行为, 请务必RTFM.
1 |
|
实现sprintf
- 实现
abstract-machine/klib/src/stdio.c中的sprintf(), 具体行为可以参考man 3 printf. 目前你只需要实现%s和%d就能通过hello-str的测试了, 其它功能(包括位宽, 精度等)可以在将来需要的时候再自行实现. - 和其它库函数相比,
sprintf()比较特殊, 因为它的参数数目是可变的. 为了获得数目可变的参数, 你可以使用C库stdarg.h中提供的宏, 具体用法请查阅man stdarg.
1 | //(辅助)将整数转换为字符串 |
重新认识计算机: 计算机是个抽象层
- 讨论在TRM上运行的程序, 我们对这些程序的需求进行分类, 来看看我们的计算机系统是如何支撑这些需求的
- 计算
- 内存申请
- 结束运行
- 打印信息
- 宏观视角:底层——>高层
- 微观视角: 程序是个状态机
- 宏观视角: 计算机是个抽象层
- 理解计算机是如何把底层的功能经过层层抽象, 最终支撑程序的运行.
基础设施(2)
bug诊断的利器 - 踪迹
- 为了提高效率, 我们可以通过
printf()来输出我们关心的某些信息. - 在软件工程领域, 记录程序执行过程的信息称为踪迹(trace). 有了踪迹信息, 我们就可以判断程序的执行过程是否符合预期, 从而进行bug的诊断.
指令执行的踪迹 - itrace
- NEMU已经实现–
itrace (instruction trace), 它可以记录客户程序执行的每一条指令. - itrace会输出指令的PC, 二进制表示以及反汇编结果
- 框架代码默认已经打开了这个功能, 客户程序执行的指令都会被记录到
build/nemu-log.txt中 - NEMU可以限制trace输出的时机, 你可以手动指定什么时候才输出它们, 甚至还可以自定义输出trace的条件. 具体如何指定, RTFSC.
- 对于一些输出规整的trace, 我们还可以通过grep, awk, sed等文本处理工具来对它们进行筛选和处理.
nemu/src/cpu/cpu-exec.c
1 | static void exec_once(Decode *s, vaddr_t pc) { |
指令环形缓冲区 - iringbuf
- 我们能不能在客户程序出错(例如访问物理内存越界)的时候输出最近执行的若干条指令呢?
- 环形缓冲区(ring buffer)
- 在每执行一条指令的时候, 就把这条指令的信息写入到环形缓冲区中
- 如果缓冲区满了, 就会覆盖旧的内容
- 客户程序出错的时候, 就把环形缓冲区中的指令打印出来, 供调试进行参考.
必做:实现iringbuf
- 根据上述内容, 在NEMU中实现iringbuf. 你可以按照自己的喜好来设计输出的格式, 如果你想输出指令的反汇编, 可以参考itrace的相关代码; 如果你不知道应该在什么地方添加什么样的代码, 你就需要RTFSC了.
- 思考在哪添加代码:
nemu/src/memory/padder.c
1
2
3
4static void out_of_bound(paddr_t addr) {
panic("address = " FMT_PADDR " is out of bound of pmem [" FMT_PADDR ", " FMT_PADDR "] at pc = " FMT_WORD,
addr, PMEM_LEFT, PMEM_RIGHT, cpu.pc);
}- panic定义在
nemu/include/debug.h
1 | //nemu/include/debug.h |
- 由此可知panic通过Assert实现
- 推出要在
assert_fail_msg()实现
- 新建
src/cpu/iringbuf.h定义环形缓冲区的数据结构和接口
1 |
|
- 新建
src/cpu/iringbuf.c,实现环形缓冲区的操作函数
1 |
|
- 在
src/cpu/cpu-exec.c的trace_and_difftest函数中,将原本打印指令的位置更改为将指令记录到缓冲区:
1 | static void trace_and_difftest(Decode *_this, vaddr_t dnpc) { |
- 在
src/cpu/cpu-exec.c中,在assert_fail_msg函数中,调用display_iringbuf()来打印缓冲区中的指令信息。
1 | void assert_fail_msg() { |
- 在
src/memory/paddr.c中添加引用
1 | static void out_of_bound(paddr_t addr) { |
- 效果
1 | Recent instructions: |
内存访问的踪迹 - mtrace
- 可以很容易地对访存的结果进行追踪, 从而记录访存的踪迹(memory trace).
必做:实现mtrace
- 这个功能非常简单, 你已经想好如何实现了: 只需要在
paddr_read()和paddr_write()中进行记录即可. 你可以自行定义mtrace输出的格式. - 不过和最后只输出一次的iringbuf不同, 程序一般会执行很多访存指令, 这意味着开启mtrace将会产生大量的输出, 因此最好可以在不需要的时候关闭mtrace. 噢, 那就参考一下itrace的相关实现吧: 尝试在Kconfig和相关文件中添加相应的代码, 使得我们可以通过menuconfig来打开或者关闭mtrace. 另外也可以实现mtrace输出的条件, 例如你可能只会关心某一段内存区间的访问, 有了相关的条件控制功能, mtrace使用起来就更加灵活了.
- 更新
Kconfig文件
1 | config MTRACE |
- 在
include/common.h中添加 mtrace 宏定义
1 |
- 在
paddr.c文件中实现mtrace
1 |
|
make menuconfig,找到Enable memory trace选项,打开即启用
- belike:
1 | MTRACE: Read from address 0x80000000, length 4 |
- 实现mtrace输出的条件, 例如你可能只会关心某一段内存区间的访问;在
paddr.c文件中实现:
1 | static bool in_mtrace_range(paddr_t addr) { |
函数调用的踪迹 - ftrace
- 要实现ftrace, 我们只需要关心函数调用和返回相关的指令就可以了.
- 我们可以在函数调用指令中记录目标地址, 表示将要调用某个函数;
- 然后在函数返回指令中记录当前PC, 表示将要从PC所在的函数返回.
- 我们很容易在相关指令的实现中添加代码来实现这些功能. 但目标地址和PC值仍然缺少程序语义, 如果我们能把它们翻译成函数名, 就更容易理解了
- 给定一个位于代码段的地址, 如何得知它位于哪一个函数
- 这就需要ELF文件中符号表(symbol table)的帮助了.
- 符号表是可执行文件的一个section, 它记录了程序编译时刻的一些信息, 其中就包括变量和函数的信息. 为了实现ftrace, 我们首先需要了解符号表中都记录了哪些信息.
- 以cpu-tests中add这个用户程序为例, 使用readelf命令查看ELF可执行文件的信息:
1 | riscv64-linux-gnu-readelf -a add-riscv32-nemu.elf |
- 符号表
- Type属性为FUNC的表项
- 仔细观察Name属性之后, 你会发现这些表项正好对应了程序中定义的函数
- 相应的Value属性正好是它们的起始地址(你可以与反汇编结果进行对比)
- 而相应的Size属性则给出了函数的大小.
思考:消失的符号
- 我们在
am-kernels/tests/cpu-tests/tests/add.c中定义了宏NR_DATA, 同时也在add()函数中定义了局部变量c和形参a, b, 但你会发现在符号表中找不到和它们对应的表项, 为什么会这样? 思考一下, 什么才算是一个符号(symbol)?
- 符号表中记录的是全局变量、函数和其他具有名称和地址的实体。局部变量和宏定义不会出现在符号表中,因为它们的作用域和生命周期局限于函数内部或预处理阶段。
- 一个符号(Symbol)通常是指在编译和链接过程中具有名称和地址的实体。以下是一些常见的符号类型:
- 全局变量(Global Variables)
- 在程序的全局作用域中定义的变量。
- 这些变量在符号表中有对应的表项,记录了它们的名称、类型和地址。
- 函数(Functions)
- 在程序中定义的函数。
- 符号表中记录了函数的名称、类型(FUNC)和起始地址。
- 常量(Constants)
- 在程序中定义的具有名称的常量。
- 这些常量在符号表中有对应的表项。
- 外部变量(External Variables)
- 在一个文件中声明但在另一个文件中定义的变量。
- 符号表中记录了这些变量的名称和类型。
- 全局变量(Global Variables)
思考:寻找”Hello World!”
- 在Linux下编写一个Hello World程序, 编译后通过上述方法找到ELF文件的字符串表, 你发现”Hello World!”字符串在字符串表中的什么位置? 为什么会这样?
- 在编译后的ELF文件中,”Hello World!”字符串通常位于.rodata(只读数据段)或.data(数据段)中,而不是在字符串表(.strtab)中。字符串表主要用于存储符号名称和调试信息,而程序中的字符串常量则存储在数据段中。
- 原因:
- 字符串表的用途:
- 字符串表(.strtab)用于存储符号名称、调试信息等与程序执行无关的字符串。
- 它主要用于链接和调试阶段,而不是程序运行时的数据存储。
- 字符串常量的存储:
- 程序中的字符串常量(如”Hello World!”)存储在数据段(如.rodata或.data)中。
- 这些段用于存储程序运行时需要访问的常量和变量。
- 字符串表的用途:
必做:实现ftrace
- 根据上述内容, 在NEMU中实现ftrace. 你可以自行决定输出的格式. 你需要注意以下内容:
- 你需要为NEMU传入一个ELF文件, 你可以通过在parse_args()中添加相关代码来实现这一功能
- 你可能需要在初始化ftrace时从ELF文件中读出符号表和字符串表, 供你后续使用
- 关于如何解析ELF文件, 可以参考man 5 elf
- 如果你选择的是riscv32, 你还需要考虑如何从jal和jalr指令中正确识别出函数调用指令和函数返回指令
- 注意, 你不应该通过readelf等工具直接解析ELF文件. 在真实的项目中, 这个方案确实可以解决问题; 但作为一道学习性质的题目, 其目标是让你了解ELF文件的组织结构, 使得将来你在必要的时候(例如在裸机环境中)可以自己从中解析出所需的信息. 如果你通过readelf等工具直接解析ELF文件, 相当于自动放弃训练的机会, 与我们设置这道题目的目的背道而驰.
- 为NEMU传入一个ELF文件, 在
src/monitor/monitor.c的parse_args()中添加:
1 | static char *elf_file = NULL; |
- 新建
nemu/src/cpu/elf_parser.c和nemu/src/cpu/elf_parser.h,
1 | //nemu/src/cpu/elf_parser.h |
- 在初始化ftrace时从ELF文件中读出符号表和字符串表, 供后续使用
1 | //nemu/src/cpu/elf_parser.c |
- 在
abstract-machine/scripts/platform/nemu.mk中添加
NEMUFLAGS += -e $(IMAGE).elf
- 在
nemu/src/cpu/cpu-exec.c中:
1 | extern FuncSymbol *func_symbols; |
- 一直没有解析ELF,调试后发现:在当前的代码实现中,只有在命令行参数中提供 -e 选项时,才会解析 ELF 文件。要实现不提供 -e 选项时自动解析 ELF 文件,可以在
nemu/src/monitor/monitor.c的init_monitor函数中添加一个默认的 ELF 文件路径,并在没有提供 -e 选项时使用这个默认路径。
1 | /* 函数调用踪迹,ftrace. */ |
- 删掉
elf_file = "default.elf";,不自动启动,需要在命令行提供-e和elf文件
- 成功!类似:
1 | Executed instruction at pc = 0x800002c4, next pc = 0x800000cc |
- 但是有点丑,
- 把
printf("Executed instruction at pc = 0x%08x, next pc = 0x%08x\n", s->pc, s->dnpc);注释后,片段如下:
- 把
1 | FTRACE: Call main at 0x800000dc |
思考:不匹配的函数调用和返回
- 如果你仔细观察上文recursion的示例输出, 你会发现一些有趣的现象. 具体地, 注释(1)处的ret的函数是和对应的call匹配的, 也就是说, call调用了f2, 而与之对应的ret也是从f2返回; 但注释(2)所指示的一组call和ret的情况却有所不同, call调用了f1, 但却从f0返回; 注释(3)所指示的一组call和ret也出现了类似的现象, call调用了f1, 但却从f3返回.
- 尝试结合反汇编结果, 分析为什么会出现这一现象.
1 | 0x8000000c: call [_trm_init@0x80000260] |
- 现象描述
- 注释(1)
- call [f2@0x800000a4]
- ret [f2]
- 这是正常的函数调用和返回,call调用了f2,并从f2返回。 - 注释(2)
- call [f1@0x8000005c]
- ret [f0]
- 这里出现了不匹配的现象,call调用了f1,但却从f0返回。 - 注释(3)
- call [f1@0x8000005c]
- ret [f3]
- 这里也出现了不匹配的现象,call调用了f1,但却从f3返回。 - 可能的原因
- 这种不匹配的现象通常是由于函数调用过程中存在间接调用或尾调用优化(Tail Call Optimization, TCO)导致的。以下是两种可能的原因:
- 间接调用
- 在函数f1内部,可能存在对其他函数(如f0或f3)的间接调用。
- 这种情况下,f1在执行过程中调用了f0或f3,并直接从这些函数返回,而不是从f1返回。 - 尾调用优化
- 尾调用优化是一种编译器优化技术,当一个函数的最后一个操作是调用另一个函数时,编译器可以优化为直接跳转到被调用函数,而不需要返回到调用者。
- 这种优化可以减少栈帧的开销,提高程序的执行效率。
- 在这种情况下,f1的最后一个操作是调用f0或f3,编译器优化为直接跳转到f0或f3,并从这些函数返回。
思考:冗余的符号表
- 在Linux下编写一个Hello World程序, 然后使用strip命令丢弃可执行文件中的符号表:
1 | gcc -o hello hello.c |
- 用readelf查看hello的信息, 你会发现符号表被丢弃了, 此时的hello程序能成功运行吗?
- 目标文件中也有符号表, 我们同样可以丢弃它:
1 | gcc -c hello.c |
- 用readelf查看hello.o的信息, 你会发现符号表被丢弃了. 尝试对hello.o进行链接:
1 | gcc -o hello hello.o |
- 你发现了什么问题? 尝试对比上述两种情况, 并分析其中的原因.
- Hello World程序: 即使符号表被丢弃,hello程序仍然能够成功运行。
- 因为可执行文件中的符号表主要用于调试和链接阶段,而不是程序运行时所需的内容。
- 程序运行时所需的所有信息(如代码和数据)已经被嵌入到可执行文件中,因此丢弃符号表不会影响程序的运行。
- 目标文件中的符号表: 在尝试链接时,发现链接失败,出现错误信息:
1 | /usr/bin/ld: hello.o: in function `main': |
- 目标文件中的符号表用于链接阶段,记录了函数和变量的名称、类型和地址等信息。
- 链接器需要这些符号信息来解析外部引用和生成最终的可执行文件。
- 如果目标文件中的符号表被丢弃,链接器将无法解析外部引用(如printf函数),导致链接失败。
AM作为基础设施
- AM的核心思想了: 通过一组抽象的API把程序和架构解耦
- 保证了运行在AM之上的代码(包括klib)都是架构无关的, 这恰恰增加了代码的可移植性.
abstract-machine中有一个特殊的架构叫native, 是用GNU/Linux默认的运行时环境来实现的AM API.- 在
abstract-machine中, 我们可以很容易地把程序编译到另一个架构上运行, 例如在am-kernels/tests/cpu-tests/目录下执行
1 | make ALL=string ARCH=native run |
- 即可将string程序编译到native并运行. 由于我们会将程序编译到不同的架构中, 因此你需要注意make命令中的ARCH参数.
1 | Exit code = 00h |
- 如果string程序没有通过测试, 终端将会输出
1 | make[1]: *** [run] Error 1 |
- 当然也有可能输出段错误等信息.
思考:奇怪的错误码
- 为什么错误码是1呢? 你知道make程序是如何得到这个错误码的吗?
- 错误码1的含义:
- 在Unix和Linux系统中,程序的退出状态码(exit code)是一个整数值,用于表示程序的执行结果。
- 通常,0表示成功,非0表示失败。
- 错误码1通常表示一般性错误(general error),即程序执行过程中发生了某种错误,但没有具体的错误类型。
- make得到错误码的过程:
- make程序通过执行命令并检查其退出状态码来确定命令是否成功。如果命令返回非0的退出状态码,make会认为该命令失败,并输出相应的错误信息
- 框架代码编译到native的时候默认链接到
glibc, 我们需要把这些库函数的调用链接到我们编写的klib来进行测试.- 我们可以通过在
abstract-machine/klib/include/klib.h中通过定义宏__NATIVE_USE_KLIB__来把库函数链接到klib. - 如果不定义这个宏, 库函数将会链接到glibc,** 可以作为正确的参考实现来进行对比**.
- 我们可以通过在
思考:这是如何实现的?
- 为什么定义宏__NATIVE_USE_KLIB__之后就可以把native上的这些库函数链接到klib? 这具体是如何发生的? 尝试根据你在课堂上学习的链接相关的知识解释这一现象.
- 当定义了宏__NATIVE_USE_KLIB__时,编译器会包含klib_impl.h,从而使用我们自己实现的klib库函数;否则,编译器会包含标准库的头文件,使用glibc的实现。
- 具体过程:
- 定义宏:在编译时定义宏__NATIVE_USE_KLIB__。
- 条件编译:编译器根据宏__NATIVE_USE_KLIB__选择性地包含klib_impl.h,从而使用我们自己实现的klib库函数。
- 链接过程:链接器在链接过程中将printf函数链接到klib_impl.c中实现的printf函数,而不是标准库中的printf函数。
测试你的klib
- 需要编写一些充分的测试用例来专门对klib的实现进行测试.
1 | +----> 测试对象 ----> 实际输出 |
选做:编写更多的测试
- 尝试理解上述测试代码是如何进行测试的, 并在
am-kernels/tests/目录下新增一个针对klib的测试集klib-tests, 测试集的文件结构可以参考am-kernels/tests/am-tests或am-kernels/kernels/hello. - 然后针对上文所述的第一类写入函数编写相应的测试代码. 编写测试的时候需要注意一些地方:
memcpy()的行为在区间重叠的时候是UB, 你可以在遍历的时候检查区间是否重叠, 若是, 则跳过此次检查; 或者使用另一个相同的数组来作为src, 这样就不会出现重叠的情况- 字符串处理函数需要额外注意\0和缓冲区溢出的问题
- 编写后, 你可以先在native上用glibc的库函数来测试你编写的测试代码, 然后在native上用这些测试代码来测试你的klib实现, 最后再在NEMU上运行这些测试代码来测试你的NEMU实现.
- 创建目录
1 | am-kernels/tests/klib-tests/ |
- 在
klib.h中包含需要测试的函数声明
1 |
|
- 在
src/test_type1.c中编写测试代码
1 |
|
- 在
Makefile中添加编译和运行测试的规则
1 | ARCH ?= native |
- 在
am-kernels/tests/klib-tests下make,
- 报错
make Makefile:7: *** 缺失分隔符。 停止。 - 改了设置的:使用Tab键时插入空格”为用缩进!
- 编译成功得到
1 | cc -I/home/xiaoyao/ics2024/am-kernels/tests/klib-tests/include -o test_type1 src/test_type1.c |
make run,成功则得到:
1 | ./test_type1 |
选做:编写更多的测试(2)
- 尝试为klib-tests添加针对第二类只读函数的测试, 例如
memcmp(),strlen()等. 思考一下, 应该如何得到函数的预期输出?
tests/klib-tests/src/test_type2.c:
1 |
|
klib.h增加:
1 | int memcmp(const void *s1, const void *s2, size_t n); |
Makefile补充为:
1 | ARCH ?= native |
make一下,然后make run:(成功!)
1 | /test_type2.c |
选做:编写更多的测试(3)
- 尝试为klib-tests添加针对格式化输出函数的测试. 你可以先通过
sprintf()把实际输出打印到一个缓冲区中, 然后通过strcmp()来和预期输出进行对比. - 你也可以考虑实现位宽, 精度, 长度修饰符等功能, 然后生成相应的测试用例来进行测试.
- 以
%d为例, 我们需要构造一些输入. 但整数的范围太大了, 不能全部遍历它们, 因此我们需要挑选一些有代表性的整数.limits.h这个C标准头文件里面包含了一些最大数和最小数的定义, 你可以打开/usr/include/limits.h来阅读它们. 一些有代表性的整数可以是:
1 | int data[] = {0, INT_MAX / 17, INT_MAX, INT_MIN, INT_MIN + 1, |
- 为了得到相应的预期输出, 我们可以先编写一个
native程序来用printf输出它们, 然后把输出结果整理到测试代码里面.cpu-tests中的预期输出也是这样生成的.
先编写一个native程序来用printf输出它们
- 在
klib-tests目录下创建一个新的文件generate_expected_output.c:
1 |
|
- 编译
generate_expected_output.c:
1 | cd /path/to/am-kernels/tests/klib-tests |
- 运行生成的可执行文件`:
1 | ./generate_expected_output |
- 输出结果为:
1 | 0 |
把输出结果整理到测试代码里面,编写nemu的测试
src/test_type3.c中编写测试代码:
1 |
|
klib.h补充函数声明:
1 | int sprintf(char *str, const char *format, ...); |
- Makefile中添加编译和运行
test_type3.c的规则:
1 | all: test_type1 test_type2 test_type3 |
make和make run:(成功!!)
1 | ./test_type3 |
Differential Testing——强大的测试工具!
- 如果有一种方法能够表达指令的正确行为, 我们就可以基于这种方法来进行类似
assert()的检查了——ISA手册。- 如果有一个ISA手册的参考实现就好了——我们用的真机。
- 我们让在NEMU中执行的每条指令也在真机中执行一次, 然后对比NEMU和真机的状态, 如果NEMU和真机的状态不一致, 我们就捕捉到error了
- 这种方法在软件测试领域称为differential testing(后续简称DiffTest).
- 进行DiffTest需要提供一个和DUT(Design Under Test, 测试对象) 功能相同但实现方式不同的REF(Reference, 参考实现)
- 然后让它们接受相同的有定义的输入, 观测它们的行为是否相同.
- 遗憾:真机上是运行了操作系统GNU/Linux的, 我们无法在native中运行编译到
x86-nemu的AM程序, 对于mips32和riscv32的程序, 真机更是无法直接运行.- 所以, 我们需要的不仅是一个ISA手册的正确实现, 而且需要在上面能正确运行$ISA-nemu的AM程序.
- 因此, 为了通过DiffTest的方法测试NEMU实现的正确性, 我们让NEMU和另一个模拟器逐条指令地执行同一个客户程序. 双方每执行完一条指令, 就检查各自的寄存器和内存的状态, 如果发现状态不一致, 就马上报告错误, 停止客户程序的执行.
- 为了方便实现DiffTest, 我们在DUT和REF之间定义了如下的一组API:
1 | // 在DUT host memory的`buf`和REF guest memory的`addr`之间拷贝`n`字节, |
- 其中寄存器状态
dut要求寄存器的成员按照某种顺序排列, 若未按要求顺序排列, difftest_regcpy()的行为是未定义的.- REF需要实现这些API, DUT会使用这些API来进行DiffTest. 在这里, DUT和REF分别是NEMU和其它模拟器.
- NEMU的框架代码已经准备好DiffTest的功能了, 在menuconfig中打开相应的选项:
1 | Testing and Debugging |
- 然后重新编译NEMU并运行即可
- riscv32: Spike. Spike是RISC-V社区的一款全系统模拟器, 它的工作原理与NEMU非常类似. 我们在Spike中增加了少量接口来实现DiffTest的API. 由于Spike包含较多源文件, 编译过程可能需要花费数分钟. 为了运行Spike, 你还需要安装另一个工具:
apt-get install device-tree-compiler
- 由于不同ISA的寄存器有所不同, 框架代码把寄存器对比抽象成一个ISA相关的API, 即
isa_difftest_checkregs()函数(在nemu/src/isa/$ISA/difftest/dut.c中定义). 你需要实现isa_difftest_checkregs()函数, 把通用寄存器和PC与从DUT中读出的寄存器的值进行比较. 若对比结果一致, 函数返回true; 如果发现值不一样, 函数返回false, 框架代码会自动停止客户程序的运行. 特别地, isa_difftest_checkregs()对比结果不一致时, 第二个参数pc应指向导致对比结果不一致的指令, 可用于打印提示信息.
选做:实现DiffTest
- 上文在介绍API约定的时候, 提到了寄存器状态r需要把寄存器按照某种顺序排列. 你首先需要RTFSC, 从中找出这一顺序, 并检查你的NEMU实现是否已经满足约束.
- 然后在isa_difftest_checkregs()中添加相应的代码, 实现DiffTest的核心功能. 实现正确后, 你将会得到一款无比强大的测试工具.
- 体会到DiffTest的强大之后, 不妨思考一下: 作为一种基础设施, DiffTest能帮助你节省多少调试的时间呢?
- 寄存器状态r需要把寄存器按照某种顺序排列. 你首先需要RTFSC, 从中找出这一顺序, 并检查你的NEMU实现是否已经满足约束.
nemu/tools/spike-diff/difftest.cc
- 实现
isa_difftest_checkregs:——将ref_c的寄存器与dut_cpu的寄存器逐一比较
1 | bool isa_difftest_checkregs(CPU_state *ref_r, vaddr_t pc) { |
make run一下,发现NEMU成功编译和运行,启用了 DiffTest 功能,并且使用了 spike-diff 作为参考动态库。
思考:匪夷所思的QEMU行为 (有点难度)
- 在一些旧版的mips32-QEMU中, 仅在上述指令的PC值后12位为0xffc时, 才会进行指令打包. 这个打包条件看上去非常奇怪, 你知道可能的原因是什么吗?
- 缓存行对齐
- 现代处理器通常使用缓存来提高内存访问速度。缓存行的大小通常是固定的,例如64字节或128字节。
- 如果PC值的后12位为0xffc,这意味着指令的地址接近一个缓存行的末尾。为了避免跨缓存行访问,QEMU可能会选择在这种情况下进行指令打包,以提高缓存命中率和指令执行效率。
- 指令预取优化
- 指令预取是处理器在执行指令之前,从内存中预先读取指令的一种技术。预取的指令通常存储在指令缓存中。
- 当PC值的后12位为0xffc时,指令地址接近一个预取块的末尾。为了确保预取块中的指令能够连续执行,QEMU可能会选择在这种情况下进行指令打包,以优化指令预取的效果。
- 特定硬件行为的模拟
- QEMU作为一个模拟器,可能需要模拟特定硬件的行为。在某些硬件平台上,指令打包可能会在特定的地址范围内触发。
- QEMU可能在PC值的后12位为0xffc时进行指令打包,以模拟这些硬件平台的行为,确保模拟器的行为与实际硬件一致。
- 历史遗留问题
使用QEMU作为REF时, 不要同时运行两份NEMU
- DiffTest会通过一个固定的端口连接到QEMU, 同时运行两份打开DiffTest的NEMU会出现以下信息:
Failed to find an available port: Address already in use - 如果你确信没有同时运行两份NEMU, 但仍然遇到上述信息, 可以通过执行以下命令把残留在后台的QEMU杀掉:
pkill -9 qemu
一键回归测试
- 以后你还需要在NEMU中加入新的功能, 为了保证加入的新功能没有影响到已有功能的实现, 你还需要重新运行这些测试用例. 在软件测试中, 这个过程称为回归测试.
- 为了提高效率, 我们为
cpu-tests提供了一键回归测试的功能:
1 | make ARCH=$ISA-nemu run |
- 即可自动批量运行cpu-tests中的所有测试, 并报告每个测试用例的运行结果.
- PA2.2结束!
输入输出
设备与CPU
- 除了纯粹的数据读写之外, 我们还需要对设备进行控制:
- 比如需要获取键盘控制器的状态, 查看当前是否有按键被按下;
- 或者是需要有方式可以查询或设置VGA控制器的分辨率.
- 所以, 在程序看来, 访问设备 = 读出数据 + 写入数据 + 控制状态.
- 既然设备也有寄存器, 一种最简单的方法就是把设备的寄存器作为接口, 让CPU来访问这些寄存器.
- 比如CPU可以从/往设备的数据寄存器中读出/写入数据, 进行数据的输入输出;
- 可以从设备的状态寄存器中读出设备的状态, 询问设备是否忙碌;
- 或者往设备的命令寄存器中写入命令字, 来修改设备的状态.
- CPU如何访问设备寄存器:
- 给设备中允许CPU访问的寄存器逐一编号, 然后通过指令来引用这些编号.
- 设备中可能会有一些私有寄存器, 它们是由设备自己维护的, 它们没有这样的编号, CPU不能直接访问它们.
- 这就是所谓的I/O编址方式, 因此这些编号也称为设备的地址.
- 常用的编址方式有两种:
端口I/O
- 一种I/O编址方式是端口映射I/O(port-mapped I/O), CPU使用专门的I/O指令对设备进行访问, 并把设备的地址称作端口号.
- 有了端口号以后, 在I/O指令中给出端口号, 就知道要访问哪一个设备寄存器了.
- 端口映射I/O
把端口号作为I/O指令的一部分, 这种方法很简单, 但同时也是它最大的缺点- 指令集为了兼容已经开发的程序, 是只能添加但不能修改的. 这意味着, 端口映射I/O所能访问的I/O地址空间的大小, 在设计I/O指令的那一刻就已经决定下来了. 所谓I/O地址空间, 其实就是所有能访问的设备的地址的集合.
- 随着设备越来越多, 功能也越来越复杂, I/O地址空间有限的端口映射I/O已经逐渐不能满足需求了.
內存映射I/O
- 内存映射I/O(memory-mapped I/O, MMIO) ,是通过不同的物理内存地址给设备编址的
- 这种编址方式将一部分物理内存的访问”重定向”到I/O地址空间中, CPU尝试访问这部分物理内存的时候, 实际上最终是访问了相应的I/O设备. 这样以后, CPU就可以通过普通的访存指令来访问设备
- 好处: 物理内存的地址空间和CPU的位宽都会不断增长, 内存映射I/O从来不需要担心I/O地址空间耗尽的问题.
思考:理解volatile关键字
- 也许你从来都没听说过C语言中有volatile这个关键字, 但它从C语言诞生开始就一直存在. volatile关键字的作用十分特别, 它的作用是避免编译器对相应代码进行优化. 你应该动手体会一下volatile的作用, 在GNU/Linux下编写以下代码:
1 | void fun() { |
- 然后使用
-O2编译代码. 尝试去掉代码中的volatile关键字, 重新使用-O2编译, 并对比去掉volatile前后反汇编结果的不同.
1 | gcc -O2 -c fun.c -o fun.o |
- 你或许会感到疑惑, 代码优化不是一件好事情吗? 为什么会有volatile这种奇葩的存在? 思考一下, 如果代码中p指向的地址最终被映射到一个设备寄存器, 去掉volatile可能会带来什么问题?
- 使用volatile关键字的反汇编结果
1 | 00000000 <fun>: |
- 编译器不会对变量p进行优化,每次访问*p时都会从内存中读取最新的值。
- 反汇编结果中保留了所有对*p的写操作。
- 去掉volatile关键字的反汇编结果
1 | 00000000 <fun>: |
- 编译器认为*p的值不会在循环中被改变,因此可能会对代码进行优化。
- 反汇编结果中,编译器优化掉了中间的写操作,只保留了最后一次写操作。
- 为什么会有volatile关键字:
- 代码优化通常是一件好事,可以提高程序的执行效率。然而,在某些情况下,优化可能会导致程序行为不符合预期。特别是当变量的值可能在程序的其他部分或外部环境中被改变时,编译器的优化可能会忽略这些变化,从而导致错误的行为。
- 如果代码中p指向的地址最终被映射到一个设备寄存器,去掉volatile可能会带来什么问题?
- 设备状态无法及时更新
- 设备寄存器的值可能会在程序执行过程中被设备硬件改变。如果编译器对访问设备寄存器的代码进行了优化,可能会导致程序无法及时读取到设备的最新状态。 - 指令被优化掉
- 编译器可能会优化掉一些关键的读写操作,导致设备无法正确接收命令或数据。例如,上述代码中的循环可能会被优化掉,导致程序无法正确等待设备状态的变化。 - 不可预测的行为
- 由于设备寄存器的值可能在程序执行过程中被外部硬件改变,去掉volatile关键字可能会导致程序行为不可预测,难以调试和维护。
状态机视角下的输入输出
- 设备是连接计算机和物理世界的桥梁.
1 | 状态机模型 | 状态机模型之外 |
- 对状态机模型的行为进行扩展——>对输入输出相关指令的行为进行建模:
- 执行普通指令时, 状态机按照TRM的模型进行状态转移
- 执行设备输出相关的指令(如x86的out指令或者RISC架构的MMIO写指令)时, 状态机除了更新PC之外, 其它状态均保持不变, 但设备的状态和物理世界则会发生相应的变化
- 执行设备输入相关的指令(如x86的in指令或者RISC架构的MMIO读指令)时, 状态机的转移将会”分叉”: 状态机不再像TRM那样有唯一的新状态了, 状态机具体会转移到哪一个新状态, 将取决于执行这条指令时设备的状态
NEMU中的输入输出
- NEMU的框架代码已经在
nemu/src/device/目录下提供了设备相关的代码,
映射和I/O方式
- 可以通过对映射的管理来将
端口映射I/O和内存映射I/O两种I/O编址方式统一起来
- 框架代码为映射定义了一个结构体类型IOMap(在
nemu/include/device/map.h中定义), 包括
- 名字
- 映射的起始地址和结束地址
- 映射的目标空间
- 一个回调函数.
- 然后在
nemu/src/device/io/map.c实现了映射的管理, 包括
- I/O空间的分配及其映射
- 映射的访问接口.
- 其中
map_read()和map_write()用于将地址addr映射到map所指示的目标空间, 并进行访问. 访问时, 可能会触发相应的回调函数, 对设备和目标空间的状态进行更新. 由于NEMU是单线程程序, 因此只能串行模拟整个计算机系统的工作, 每次进行I/O读写的时候, 才会调用设备提供的回调函数(callback).- 基于这两个API, 我们就可以很容易实现端口映射I/O和内存映射I/O的模拟了.
nemu/src/device/io/port-io.c是对端口映射I/O的模拟.add_pio_map()函数用于为设备的初始化来注册一个端口映射I/O的映射关系.pio_read()和pio_write()是面向CPU的端口I/O读写接口, 它们最终会调用map_read()和map_write(), 对通过add_pio_map()注册的I/O空间进行访问.- 内存映射I/O的模拟是类似的,
paddr_read()和paddr_write()会判断地址addr落在物理内存空间还是设备空间,
- 若落在物理内存空间, 就会通过
pmem_read()和pmem_write()来访问真正的物理内存; - 若落在设备空间, 就通过
map_read()和map_write()来访问相应的设备. - 从这个角度来看, 内存和外设在CPU来看并没有什么不同, 只不过都是一个字节编址的对象而已.
设备
- 为了开启设备模拟的功能, 你需要在menuconfig选中相关选项:
1 | [*] Devices ---> |
- 重新编译后, 你会看到运行NEMU时会弹出一个新窗口, 用于显示VGA的输出(见下文). 需要注意的是, 终端显示的提示符(nemu)仍然在等待用户输入, 此时窗口并未显示任何内容.
- NEMU使用SDL库来实现设备的模拟,
nemu/src/device/device.c含有和SDL库相关的代码.init_device()函数主要进行以下工作:- 调用
init_map()进行初始化. - 对上述设备进行初始化, 其中在初始化VGA时还会进行一些和SDL相关的初始化工作, 包括创建窗口, 设置显示模式等;
- 然后会进行定时器(alarm)相关的初始化工作. 定时器的功能在PA4最后才会用到, 目前可以忽略它.
- 调用
- 另一方面,
cpu_exec()在执行每条指令之后就会调用device_update()函数, 这个函数首先会检查距离上次设备更新是否已经超过一定时间, 若是, 则会尝试刷新屏幕, 并进一步检查是否有按键按下/释放, 以及是否点击了窗口的X按钮; 否则则直接返回, 避免检查过于频繁, 因为上述事件发生的频率是很低的.
将输入输出抽象成IOE
- 与TRM不同, 设备访问是为计算机提供输入输出的功能, 因此我们把它们划入一类新的API, 名字叫IOE(I/O Extension).
- 访问设备 = 读/写操作
- IOE提供三个API:
1 | bool ioe_init(); |
- 第一个API用于进行IOE相关的初始化操作.
- 后两个API分别用于从编号为reg的寄存器中读出内容到缓冲区buf中, 以及往编号为reg寄存器中写入缓冲区buf中的内容.
- 需要注意的是, 这里的reg寄存器并不是上文讨论的设备寄存器, 因为设备寄存器的编号是架构相关的. 在IOE中, 我们希望采用一种架构无关的”抽象寄存器”, 这个reg其实是一个功能编号, 我们约定在不同的架构中, 同一个功能编号的含义也是相同的, 这样就实现了设备寄存器的抽象.
abstract-machine/am/include/amdev.h中定义了常见设备的”抽象寄存器”编号和相应的结构.- 这些定义是架构无关的, 每个架构在实现各自的IOE API时, 都需要遵循这些定义(约定).
- 为了方便地对这些抽象寄存器进行访问,
klib中提供了io_read()和io_write()这两个宏, 它们分别对ioe_read()和ioe_write()这两个API进行了进一步的封装.
- 特别地, NEMU作为一个平台, 设备的行为是与ISA无关的, 因此我们只需要在
abstract-machine/am/src/platform/nemu/ioe/目录下实现一份IOE, 来供NEMU平台的架构共享. 其中,abstract-machine/am/src/platform/nemu/ioe/ioe.c中实现了上述的三个IOE API, ioe_read()和ioe_write()都是通过抽象寄存器的编号索引到一个处理函数, 然后调用它. - 处理函数的具体功能和寄存器编号相关, 下面我们来逐一介绍NEMU中每个设备的功能.
串口
- 串口是最简单的输出设备.
nemu/src/device/serial.c模拟了串口的功能
必做:运行Hello World
- 如果你选择的是mips32和riscv32, 你不需要实现额外的代码, 因为NEMU的框架代码已经支持MMIO了.
- 实现后,
在am-kernels/kernels/hello/目录下键入
1 | make ARCH=riscv32-nemu run |
- 如果你的实现正确, 你将会看到程序往终端输出一些信息(请注意不要让输出淹没在调试信息中).
- 需要注意的是, 这个hello程序和我们在程序设计课上写的第一个hello程序所处的抽象层次是不一样的: 这个hello程序可以说是直接运行在裸机上, 可以在AM的抽象之上直接输出到设备(串口); 而我们在程序设计课上写的hello程序位于操作系统之上, 不能直接操作设备, 只能通过操作系统提供的服务进行输出, 输出的数据要经过很多层抽象才能到达设备层. 我们会在PA3中进一步体会操作系统的作用.
am-kernels/kernels/hello/hello.c中代码:
1 |
|
HIT GOOD TRAP at pc = 0x800000b0
- 输出
Hello, AbstractMachine!/n和mainargs = ''.\n - 在AM中, main()函数允许带有一个字符串参数, 这一参数通过mainargs指定, 并由AM的运行时环境负责将它传给main()函数, 供AM程序使用. 具体的参数传递方式和架构相关.例如你可以在运行hello的时候给出一个字符串参数:
make ARCH=riscv32-nemu run mainargs=I-love-PA- 输出
Hello, AbstractMachine!/n和mainargs = 'I-love-PA'.\n
- 输出
必做:实现printf
- 有了
putch(), 我们就可以在klib中实现printf()了. - 你之前已经实现了
sprintf()了, 它和printf()的功能非常相似, 这意味着它们之间会有不少重复的代码. 你已经见识到Copy-Paste编程习惯的坏处了, 思考一下, 如何简洁地实现它们呢? - 实现了
printf()之后, 你就可以在AM程序中使用输出调试法了.
- 在
ics2024/abstract-machine/klib/src/stdio.c中:
1 | static char *number(char *str, unsigned int num, int base, int is_upper) { |
必做:运行alu-tests
- 我们在
am-kernels/tests/alu-tests/目录下移植了一个专门测试各种C语言运算的程序, 实现printf()后你就可以运行它了. 编译过程可能需要花费1分钟. make ARCH=riscv32-nemu runHIT GOOD TRAP at pc = 0x800ebb34- 但是没有printf输出,不知道为什么
时钟
必做:实现IOE
- 在
abstract-machine/am/src/platform/nemu/ioe/timer.c中实现AM_TIMER_UPTIME的功能. 在abstract-machine/am/src/platform/nemu/include/nemu.h和abstract-machine/am/src/$ISA/$ISA.h中有一些输入输出相关的代码供你使用. - 实现后, 在
$ISA-nemu中运行am-kernel/tests/am-tests中的real-time clock test测试. 如果你的实现正确, 你将会看到程序每隔1秒往终端输出一行信息. 由于我们没有实现AM_TIMER_RTC, 测试总是输出1900年0月0日0时0分0秒, 这属于正常行为, 可以忽略.
- 实现:
1 | void __am_timer_uptime(AM_TIMER_UPTIME_T *uptime) { |
- 不正确,之后有修改。修改后:
1 | void __am_timer_uptime(AM_TIMER_UPTIME_T *uptime) { |
- 要如何运行
real-time clock test这个测试, 就交给你来RTFSC吧:
- 在
am-kernels/tests/am-tests/src/main.c中
1 |
|
- 所以输入命令为
make ARCH=riscv32-nemu run mainargs=t
- 成功,部分为:
1 | 1900-0-0 %02d:%02d:%02d GMT (1 second). |
看看NEMU跑多快
- 有了时钟之后, 我们就可以测试一个程序跑多快, 从而测试计算机的性能. 尝试在NEMU中依次运行以下benchmark(已经按照程序的复杂度排序, 均在am-kernel/benchmarks/目录下; 另外跑分时请关闭NEMU的监视点, trace以及DiffTest, 同时取消menuconfig中的 Enable debug information并重新编译NEMU, 以获得较为真实的跑分):
- dhrystone
- coremark
- microbench
- 成功运行后会输出跑分. 其中microbench跑分以i9-9900K @ 3.60GHz的处理器为参照, 100000分表示与参照机器性能相当, 100分表示性能为参照机器的千分之一. 除了和参照机器比较之外, 也可以和小伙伴进行比较. 如果把上述benchmark编译到native, 还可以比较native的性能.
- 另外, microbench提供了四个不同规模的测试集, 包括test, train, ref和huge. 你可以先运行test规模, 它可以较快地运行结束, 来检查NEMU实现的正确性, 然后再运行ref规模来测量性能. 具体的运行方法请阅读README.
- 此外, huge规模一般用于真机的测试, 在NEMU中需要运行很长时间, 我们不要求你运行它.
- 都报错
1 | make[1]: *** [/home/xiaoyao/ics2024/nemu/scripts/native.mk:38: run] 浮点异常 (核心已转储) |
- 关于
AM_TIMER_UPTIME的实现, 我们在框架代码中埋了一些小坑, 如果你没有修复相关的问题, 你可能会在运行benchmark的时候出现跑分不正确的现象. 这是为了强迫大家认真RTFSC了解程序运行过程中的一切细节:benchmark读取时钟信息的时候, 整个计算机系统究竟发生了什么? 只有这样你才能把时钟相关的bug调试正确.
am-kernels/benchmarks/dhrystone/dry.c中944行有除0错误:
1 | printf("Dhrystone %s %d Marks\n", pass ? "PASS" : "FAIL", |
- 修改
time.c
1 | void __am_timer_uptime(AM_TIMER_UPTIME_T *uptime) { |
- Dhrystone:
1 | Dhrystone Benchmark, Version C, Version 2.2 |
- coremark:
- 报错!
- 查看
benchmarks/coremark/build/coremark-riscv32-nemu.txt 80000df4: 00178783 lb a5,1(a5)
INSTPAT("??????? ????? ????? 000 ????? 00000 11", lb , I, R(rd) = SEXT(Mr(src1 + imm, 1), 8));//lb,将src1+imm地址的值的低8位存入rd
80000968: 08046413 ori s0,s0,128
INSTPAT("??????? ????? ????? 110 ????? 00100 11", ori , I, R(rd) = src1 | imm); //ori,或立即数,将src1的值与imm进行或运算,结果存入rd
1 | CoreMark PASS 118 Marks |
- microbench
- 报错!
- 查看:
benchmarks/microbench/build/microbench-riscv32-nemu.txt 80004a54: 02f535b3 mulhu a1,a0,a5
INSTPAT("0000001 ????? ????? 011 ????? 01100 11", mulhu , R, R(rd) = ((uint64_t)src1 * (uint64_t)src2) >> 32);//mulhu
1 | MicroBench PASS 153 Marks |
- 正确实现时钟后, 你就可以在NEMU上运行一些具有展示性的程序了: 我们在
am-kernels/kernels/demo/目录下移植了一些小型演示程序 - 为了运行它们, 你还需要实现
klib中的malloc()和free(), 目前你可以实现一个简单的版本:- 在
malloc()中维护一个上次分配内存位置的变量addr, 每次调用malloc()时, 就返回[addr, addr + size)这段空间.addr的初值设为heap.start, 表示从堆区开始分配. 你也可以参考microbench中的相关代码. 注意malloc()对返回的地址有一定的要求, 具体情况请RTFM. free()直接留空即可, 表示只分配不释放. 目前NEMU中的可用内存足够运行各种测试程序.
- 在
选做:
设备访问的踪迹 - dtrace
必做:实现dtrace
- 这个功能非常简单, 你可以自行定义
dtrace输出的格式. 注意你可以通过map->name来获取一段设备地址空间的名字, 这样可以帮助你输出可读性较好的信息. 同样地, 你也可以为dtrace实现条件控制功能, 提升dtrace使用的灵活性.
- 在Kconfig中定义DTRACE,
nemu/Kconfig:
1 | menu "Tracing Options" |
- 在
map_read和map_write函数中添加dtrace功能:nemu/src/device/io/map.c:
1 | word_t map_read(paddr_t addr, int len, IOMap *map) { |
- 成功,片段如下:
1 | [src/device/io/map.c:61 map_read] address = 0xa0000060 read 0x00000000 at device = keyboard |
键盘
- 一般键盘的工作方式如下: 当按下一个键的时候, 键盘将会发送该键的通码(make code); 当释放一个键的时候, 键盘将会发送该键的断码(break code).
nemu/src/device/keyboard.c- 每当用户敲下/释放按键时, 将会把相应的键盘码放入数据寄存器, CPU可以访问数据寄存器, 获得键盘码; 当无按键可获取时, 将会返回AM_KEY_NONE.
abstract-machine/am/include/amdev.h中为键盘的功能定义了一个抽象寄存器:AM_INPUT_KEYBRD, AM键盘控制器, 可读出按键信息.keydown为true时表示按下按键, 否则表示释放按键.keycode为按键的断码, 没有按键时,keycode为AM_KEY_NONE.
必做:实现IOE(2)
- 在
abstract-machine/am/src/platform/nemu/ioe/input.c中实现AM_INPUT_KEYBRD的功能. 实现后, 在$ISA-nemu中运行am-tests中的readkey test测试. 如果你的实现正确, 在程序运行时弹出的新窗口中按下按键, 你将会看到程序输出相应的按键信息, 包括按键名, 键盘码, 以及按键状态.
am/src/platform/nemu/ioe/input.c:
1 | void __am_input_keybrd(AM_INPUT_KEYBRD_T *kbd) { |
tests/am-tests/src/main.c中:['k'] = "readkey test"
make ARCH=riscv32-nemu run mainargs=k
- 成功:
1 | Got (kbd): Y (34) DOWN |
思考:如何检测多个键同时被按下?
- 在游戏中, 很多时候需要判断玩家是否同时按下了多个键, 例如RPG游戏中的八方向行走, 格斗游戏中的组合招式等等. 根据键盘码的特性, 你知道这些功能是如何实现的吗?
- 思路:
- 使用数组或位图记录按键状态
- 使用一个数组或位图来记录每个按键的状态(按下或释放)。
- 当接收到按键事件时,更新相应的数组或位图。
- 检测多个键同时按下
- 在游戏逻辑中,检查数组或位图中多个按键的状态,判断是否同时按下了这些按键。
VGA
- VGA可以用于显示颜色像素, 是最常用的输出设备.
nemu/src/device/vga.c模拟了VGA的功能
思考:神奇的调色板
- 现代的显示器一般都支持24位的颜色(R, G, B各占8个bit, 共有2^82^82^8约1600万种颜色), 为了让屏幕显示不同的颜色成为可能, 在8位颜色深度时会使用调色板的概念. 调色板是一个颜色信息的数组, 每一个元素占4个字节, 分别代表R(red), G(green), B(blue), A(alpha)的值. 引入了调色板的概念之后, 一个像素存储的就不再是颜色的信息, 而是一个调色板的索引: 具体来说, 要得到一个像素的颜色信息, 就要把它的值当作下标, 在调色板这个数组中做下标运算, 取出相应的颜色信息. 因此, 只要使用不同的调色板, 就可以在不同的时刻使用不同的256种颜色了.
- 在一些90年代的游戏中(比如仙剑奇侠传), 很多渐出渐入效果都是通过调色板实现的, 聪明的你知道其中的玄机吗?
- 可以通过动态修改调色板中的颜色信息来实现渐变效果。例如,可以逐步调整调色板中的颜色值,使得屏幕上的图像逐渐变暗或变亮。
- 在AM中, 显示相关的设备叫GPU, GPU是一个专门用来进行图形渲染的设备. 在NEMU中, 我们并不支持一个完整GPU的功能, 而仅仅保留绘制像素的基本功能.
abstract-machine/am/include/amdev.h中为GPU定义了五个抽象寄存器, 在NEMU中只会用到其中的两个:AM_GPU_CONFIG, AM显示控制器信息, 可读出屏幕大小信息width和height. 另外AM假设系统在运行过程中, 屏幕大小不会发生变化.AM_GPU_FBDRAW, AM帧缓冲控制器, 可写入绘图信息, 向屏幕(x, y)坐标处绘制w*h的矩形图像. 图像像素按行优先方式存储在pixels中, 每个像素用32位整数以00RRGGBB的方式描述颜色. 若sync为true, 则马上将帧缓冲中的内容同步到屏幕上.
必做:实现IOE(3)
- 事实上, VGA设备还有两个寄存器: 屏幕大小寄存器和同步寄存器. 我们在讲义中并未介绍它们, 我们把它们作为相应的练习留给大家. 具体地, 屏幕大小寄存器的硬件(NEMU)功能已经实现, 但软件(AM)还没有去使用它; 而对于同步寄存器则相反, 软件(AM)已经实现了同步屏幕的功能, 但硬件(NEMU)尚未添加相应的支持.
- 好了, 提示已经足够啦, 至于要在什么地方添加什么样的代码, 就由你来RTFSC吧. 这也是明白软硬件如何协同工作的很好的练习. 实现后, 向__am_gpu_init()中添加如下测试代码:
1 | --- abstract-machine/am/src/platform/nemu/ioe/gpu.c |
- 其中上述代码中的w和h并未设置正确的值, 你需要阅读am-tests中的display test测试, 理解它如何获取正确的屏幕大小, 然后修改上述代码的w和h. 你可能还需要对gpu.c中的代码进行一些修改. 修改后, 在$ISA-nemu中运行am-tests中的display test测试, 如果你的实现正确, 你会看到新窗口中输出了全屏的颜色信息.
nemu/src/device/vga.c中vga_update_screen(),调用update_screen函数并将同步寄存器清零:
1 | void vga_update_screen() { |
abstract-machine/am/src/platform/nemu/ioe/gpu.c
1 | void __am_gpu_config(AM_GPU_CONFIG_T *cfg) { |
abstract-machine/am/src/platform/nemu/ioe/gpu.c
1 | void __am_gpu_init() { |
- 运行
['v'] = "display test":make ARCH=riscv32-nemu run mainargs=v
必做:实现IOE(4)
- 事实上, 刚才输出的颜色信息并不是display test期望输出的画面, 这是因为AM_GPU_FBDRAW的功能并未正确实现. 你需要正确地实现AM_GPU_FBDRAW的功能. 实现后, 重新运行display test. 如果你的实现正确, 你将会看到新窗口中输出了相应的动画效果.
- 实现正确后, 你就可以去掉上文添加的测试代码了.
abstract-machine/am/src/platform/nemu/ioe/gpu.c:
1 | void __am_gpu_fbdraw(AM_GPU_FBDRAW_T *ctl) { |
- 去掉测试代码
- 运行
['v'] = "display test":make ARCH=riscv32-nemu run mainargs=v
1 | 3264: FPS = 2 |
冯诺依曼计算机系统
展示你的计算机系统
- 完整实现IOE后, 我们还可以运行一些酷炫的程序:
- 幻灯片播放(在
am-kernels/kernels/slider/目录下). 程序将每隔5秒切换images/目录下的图片.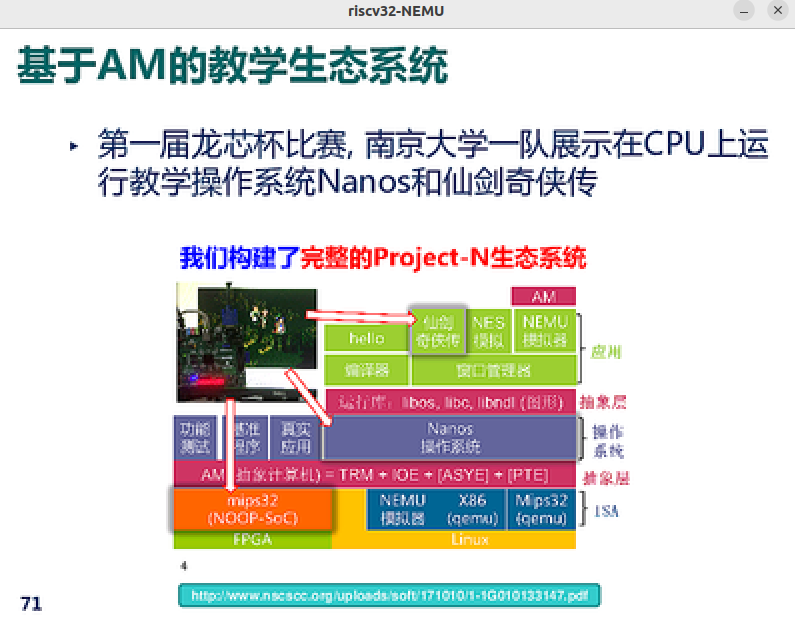
- 打字小游戏(在
am-kernels/kernels/typing-game/目录下).
Hit: 4; Miss: 172; Wrong: 25,好快哈哈哈
- (略)
- 事实上, 游戏可以抽象成一个死循环:
1 | while (1) { |
- 我们的计算机添加IOE之后, 完全可以通过AM的抽象支撑起循环体中的功能, 所以要在NEMU中运行这些酷炫的游戏, 并不是不可能的. 甚至我们也可以把刚才运行的am-tests测试中的死循环看成是一些简化的游戏. 你将要在PA3中运行的复杂游戏仙剑奇侠传, 背后也是这样的一个死循环.
必做:游戏是如何运行的
- 请你以打字小游戏为例, 结合”程序在计算机上运行”的两个视角, 来剖析打字小游戏究竟是如何在计算机上运行的. 具体地, 当你按下一个字母并命中的时候, 整个计算机系统(NEMU, ISA, AM, 运行时环境, 程序) 是如何协同工作, 从而让打字小游戏实现出”命中”的游戏效果?
- 打字小游戏只有不到200行的简单代码, 非常适合大家RTFSC. 如果你发现自己难以理解打字小游戏的具体行为, 你需要给自己敲响警钟了: 你在做PA的时候很有可能只关注怎么把必做内容的代码写对, 而不去思考这些代码和计算机系统的关系. 从ICS和PA的角度来说, 这种做法是不及格的, 而且很快你就会吃苦头了.
- RTFSC-程序视角:
- 初始化:
- main() 函数首先调用 ioe_init() 和 video_init() 函数来初始化输入输出设备和视频显示。
- ioe_init() 初始化输入输出环境。
- video_init() 初始化屏幕宽度和高度,并设置字符纹理和背景颜色。 - 主循环:
- main() 函数进入一个无限循环,持续更新游戏逻辑和渲染屏幕。
- 在每一帧中,游戏逻辑通过 game_logic_update() 函数更新,处理字符的移动和状态。
- render() 函数负责将字符绘制到屏幕上,并显示命中、错过和错误的统计信息。 - 输入处理:
- 在每一帧中,游戏通过 io_read(AM_INPUT_KEYBRD) 函数读取键盘输入事件。
- 如果按下的键是 ESC,游戏调用 halt(0) 函数退出。
- 如果按下的键是字母键,游戏调用 check_hit() 函数检查是否命中字符。 - 命中处理:
- check_hit() 函数遍历所有字符,检查按下的键是否与字符匹配,并且字符是否在屏幕上。
- 如果命中,更新命中统计信息,并将字符的速度设置为负值,使其向上移动。
- 如果未命中,更新错误统计信息。
- 系统视角
- NEMU:
- NEMU用于模拟计算机硬件环境。它执行打字小游戏的二进制代码,并模拟 CPU、内存和外设。
- 当游戏运行时,NEMU 负责解释和执行每一条指令,并处理硬件中断和设备 I/O。 - ISA:
- ISA 定义了 CPU 支持的指令集和寄存器。打字小游戏的二进制代码是基于特定 ISA 编译的。
- NEMU 根据 ISA 解释和执行指令,更新寄存器和内存状态。 - AM:
- AM 提供了一组抽象的硬件接口,使得程序可以在不同的硬件平台上运行。
- 打字小游戏通过 AM 提供的接口(如 io_read() 和 io_write())与硬件交互,而不需要关心底层硬件的具体实现。 - 运行时环境:
- 运行时环境包括操作系统和库函数,提供程序运行所需的基本服务。
- 打字小游戏依赖于运行时环境提供的输入输出、内存管理和中断处理等功能。 - 按下一个字母并命中的过程:
- 按下字母键:
- 用户按下一个字母键,键盘控制器生成一个键盘中断。
- NEMU 捕获键盘中断,并调用相应的中断处理程序。 - 处理键盘中断:
- 中断处理程序读取键盘输入,并将键码存储在输入缓冲区中。
- 游戏主循环调用 io_read(AM_INPUT_KEYBRD) 函数读取键盘输入事件。 - 检查命中:
- 游戏调用 check_hit() 函数,遍历所有字符,检查按下的键是否与字符匹配。
- 如果命中,更新命中统计信息,并将字符的速度设置为负值,使其向上移动。 - 更新屏幕:
- 游戏调用 render() 函数,将字符绘制到屏幕上,并显示命中、错过和错误的统计信息。
- NEMU 模拟 GPU,将绘制的内容显示在屏幕上。
必答题:
程序是个状态机
- 已完成,在“不停计算的机器”
RTFSC 请整理一条指令在NEMU中的执行过程
- 已完成,在“RTFSC(2)”的“运行第一个C程序”中
程序如何运行 理解打字小游戏如何运行
- 已完成,就在上面
编译与链接
- 在
nemu/include/cpu/ifetch.h中, 你会看到由static inline开头定义的inst_fetch()函数. 分别尝试去掉static, 去掉inline或去掉两者, 然后重新进行编译, 你可能会看到发生错误. 请分别解释为什么这些错误会发生/不发生? 你有办法证明你的想法吗?
- 去掉
static:
- 无错误
- 原因:去掉
static后,函数inst_fetch仍然是内联函数。内联函数在编译时会将函数体直接插入到调用点,因此不会产生多重定义的问题。
- 去掉
inline:
- 无错误
- 原因:去掉
inline后,函数inst_fetch仍然是静态函数。静态函数的作用域仅限于定义它的文件,因此不会产生多重定义的问题。
- 去掉两者:
- 报错:
1 | /usr/bin/ld: /home/xiaoyao/ics2024/nemu/build/obj-riscv32-nemu-interpreter/src/isa/riscv32/inst.o: in function `inst_fetch': |
- 原因:去掉
static和inline后,函数inst_fetch变成了一个普通的全局函数。由于头文件ifetch.h会被多个源文件包含,因此会导致多个源文件中都定义了inst_fetch函数,从而在链接时产生多重定义错误。
编译与链接
- 在
nemu/include/common.h中添加一行volatile static int dummy; 然后重新编译NEMU. 请问重新编译后的NEMU含有多少个dummy变量的实体? 你是如何得到这个结果的? - 一共有:37个
- 方法:每个包含
common.h的源文件都会打印dummy变量的地址,从而确认dummy变量的数量(数出37个)
1 |
|
- 原因:
- 重新编译后的 NEMU 含有多个 dummy 变量的实体。每个包含 common.h 的源文件都会有一个独立的 dummy 变量。
- static 关键字使得 dummy 变量在每个源文件中都是局部的,因此每个包含 common.h 的源文件都会有一个独立的 dummy 变量。 - 添加上题中的代码后, 再在nemu/include/debug.h中添加一行
volatile static int dummy; 然后重新编译NEMU. 请问此时的NEMU含有多少个dummy变量的实体? 与上题中dummy变量实体数目进行比较, 并解释本题的结果. - 一共有:37个
- 方法:输出+数
1 | //common.h |
- 比较:结果相同。
- 原因:
- static 关键字使得 dummy 变量在每个源文件中都是局部的,即每个包含 common.h 和 debug.h 的源文件都会有一个独立的 dummy 变量。
- volatile 关键字告诉编译器该变量可能会被外部因素修改,因此编译器不会对该变量进行优化。
- debug.h 包含了 common.h,因此每个包含 debug.h 的源文件中会有两个 dummy 变量,一个来自 common.h,一个来自 debug.h。 - 修改添加的代码, 为两处dummy变量进行初始化:volatile static int dummy = 0; 然后重新编译NEMU. 你发现了什么问题? 为什么之前没有出现这样的问题? (回答完本题后可以删除添加的代码.)
- 报错,重复定义
- 报错原因:
- static 关键字:
- static关键字使得变量在每个源文件中都是局部的,即每个包含 common.h 和 debug.h 的源文件都会有一个独立的 dummy 变量。
- 但是,当在头文件中初始化 static 变量时,编译器会尝试在每个包含该头文件的源文件中定义并初始化该变量。这会导致多个定义冲突。
- static 关键字:
- 之前没有出现这样的问题是因为:
- 未初始化的 static 变量:
- 当 static 变量未初始化时,编译器只会在每个包含该头文件的源文件中生成该变量的声明,而不会生成定义和初始化代码。
- 因此,每个源文件都会有一个独立的 dummy 变量,而不会导致多个定义冲突。
- 未初始化的 static 变量:
了解Makefile
- 请描述你在
am-kernels/kernels/hello/目录下敲入make ARCH=$ISA-nemu后, make程序如何组织.c和.h文件, 最终生成可执行文件am-kernels/kernels/hello/build/hello-$ISA-nemu.elf.(这个问题包括两个方面:Makefile的工作方式和编译链接的过程.) 关于Makefile工作方式的提示:- Makefile中使用了变量, 包含文件等特性
- Makefile运用并重写了一些implicit rules
- 在man make中搜索-n选项, 也许会对你有帮助
- RTFM
- Makefile 工作方式
- 变量和包含文件
- 在am-kernels/kernels/hello/Makefile中是以下内容:1
2
3NAME = hello
SRCS = hello.c
include $(AM_HOME)/Makefile
-NAME变量定义了目标文件的名称。
-SRCS变量定义了源文件。
-include $(AM_HOME)/Makefile包含了$(AM_HOME)/Makefile文件中的内容 - 隐式规则和重写
- Makefile 使用了一些隐式规则和重写规则来简化编译和链接过程。隐式规则是 make 的默认规则,可以自动推断如何编译和链接文件。 - 编译链接过程
- 解析 Makefile
- 当你在 am-kernels/kernels/hello/ 目录下敲入 make ARCH=$ISA-nemu 时,make 程序首先解析 Makefile。 - 包含 $(AM_HOME)/Makefile
- make 程序解析 include $(AM_HOME)/Makefile,将 $(AM_HOME)/Makefile 文件的内容包含进来。假设 $(AM_HOME) 是 am-kernels/abstract-machine 目录。 - 解析 $(AM_HOME)/Makefile
- 在 $(AM_HOME)/Makefile 中,定义了一些通用规则和变量,用于编译和链接不同的目标文件。 - 编译源文件
- make 程序根据隐式规则和重写规则,首先编译源文件 hello.c - 链接目标文件
- 编译完成后,make 程序链接目标文件 hello.o,生成可执行文件 hello-$ISA-nemu.elf
If you like my blog, you can approve me by scanning the QR code below.

